Mean, Median and Mode
What is the mean?
The mean measures the center of a set of data values. For continuous data, the mean is the average of the data values.
How is the mean used?
The mean of a sample of data values is used to estimate the true unknown population mean. The mean is often used as a simple summary statistic of a set of data. It is used in conjunction with the standard deviation for calculating statistical intervals, hypothesis test statistics and control chart limits.
What are some issues to think about regarding the mean?
The mean can be affected by extreme values. When you have extreme values or a skewed distribution, the median may be a better measure of the center. Before using the mean, check your data for extreme values, and look at a graph to see if the data is roughly symmetrical.
What is the median?
The median is the 50th percentile of the sample data. In other words, 50% of the data values are above the median, and 50% are below the median. The median is another estimate of the center of the data in your sample.
What is the mode?
The mode is the most frequently occurring value in your data. A data set containing no repeating values does not have a mode. A data set with multiple values repeating at the same frequency can have multiple modes. The mode is another statistic used to estimate the center of data.
The mean describes the center of a data set
Suppose you have a set of data values and plot them as shown in Figure 1. The horizontal axis shows your data values. The vertical axis shows how many points have a given data value. In statistical terms, this is a histogram or distribution of data values. The mean estimates the center of the data.

What is the population mean?
The population mean is the center of the theoretical population and is often unknown.
Let’s think about an example where you know the population. Suppose you want to know the mean wind speed at landfall of Atlantic hurricanes since 1950. This is a relatively small population. Data is available for all Atlantic hurricanes since 1950 that have made landfall. You can easily calculate the population mean.
But in many cases, you will not know the true population mean because you will not have data on the entire population.
The population mean is shown in formulas by the Greek letter for “small m” or “mu.” The symbol is μ.
What is the sample mean?
To estimate the unknown population mean, you collect a sample of data and then calculate the mean of that sample.
The sample mean measures the center of the data in your sample. This is an estimate of the population mean.
The statistical symbol for sample mean in formulas is an x with a line or bar above it; it is called an "x bar" and it looks like x̅.
What is the difference between the sample mean, arithmetic mean and sample average?
These are three terms used for the sample mean. They are the same.
Since the population mean is often unknown, you will see the term “mean” used for “sample mean.” When you read articles that mention the “mean income” or “mean temperature,” these articles usually refer to the mean of the sample data.
It’s not true that 50% are 'above average'
Many people make a common mistake of assuming that 50% of the data values are above the sample mean and 50% are below it. This is often not true. This mistake mixes up the mean and the median. The mean and median are the same only in some situations.
How to calculate the mean
To calculate the mean, you add up all the numbers for the data values in your sample and then divide by how many data values you have. Let's explore this calculation with a simple example.
Suppose your data values are 4, 5 and 6. To calculate the mean:
$\frac{(4+5+6)}{3} = \frac{15}{3} = 5$
Typically you will use software to calculate the mean. The formula for the mean is:
$\overline{x}=\frac{Σx_i}{n}$
In the formula above, the sample has n data values. Each data value is represented by xi. The summation symbol $Σ$ means that the data values should be added up, just as we did in the example.
For the unknown population mean, the size of the population is often shown as a capital N. In the rare situation where you can calculate the population mean, the formula is the same and uses N instead of n.
The median
The median is the 50th percentile of the sample data. It’s always true that 50% of the data values are above the median, and 50% are below the median. Just like with the mean, we have a true unknown population median and a sample median. The true population median is rarely known.
Both the mean and the median estimate the center of your data, and both are often reported. As we shall see below, the median is less affected by extreme data values or by data that is not symmetrical.
How to calculate the median
To calculate the median, you first order the sample data values from low to high and then find the middle value.
This is easier to understand with a couple of simple examples.
Suppose your data values are again 4, 5 and 6.
First, order the values from low to high: 4 – 5 – 6.
The middle value, which in this example is 5, is the median. Half of the data are above the median and half are below.
For a second example, suppose you have an even number of data values in your sample, let's say 7, 4, 5 and 6. There is no single middle value.
First, order the data values from low to high: 4 – 5 – 6 – 7.
Second, find the two middle values: 5 and 6.
Third, take the average of these two values by adding the two values and dividing by 2. The result is the median. In our example:
$\frac{5+6}{2} = \frac{11}{2} = 5.5$
In both of these examples, the median is the middle value. Half of the sample data is above the median and half is below.
For the second example, we have 4, 5, 5.5, 6, 7, so the median of 5.5 is in the middle of the ordered sample values for the data.
Typically you will use software to calculate the median.
The mode
The mode is another statistic used to estimate the center of data. The mode is the most frequently occurring value.
For example, suppose your data values are 3, 4, 4, 4, 5 and 6.
The mode is 4 because it is the most frequent value.
Most statistical software calculates the mode. However, in practice, the mode is not used as often as the mean or the median; we'll focus on those latter two for the remainder of this page.
How extreme data values affect the sample mean and sample median
The sample mean can be sensitive to extreme data values. Slightly altering the example above, suppose the sample data values are now 4, 5 and 12.
The sample mean is:
$\frac{4+5+12}{3} = \frac{21}{3} = 7$
The sample median is the middle value of the ordered data values 4 – 5 – 12, which is 5.
Compare this with the earlier example. The data values of 4, 5 and 6 had a mean and median of 5. By changing a single data value from 6 to 12, the median did not change, but the mean changed from 5 to 7.
For larger data sets, a single extreme data value can have a larger impact on the sample mean but a smaller impact on the sample median. We say that the median is robust to outliers or extreme data values.
The distributions below show a data set with an outlier excluded (Figure 2) and then with the outlier included (Figure 3).


Both sets of data have a median of 44.6. The data without the outlier has a mean of 45.3, and the data with the outlier has a mean of 45.6. Both histograms have an axis scale of 20 to 90.
CAUTION! Don’t delete an extreme data value just because it’s there. You should try to find out if the extreme data value is an error or an anomaly. If it is an error, then you should try to correct the value. If you cannot identify the value as an error, then you should not omit the extreme data value. In this situation, you may decide to report your analysis both with and without the questionable data point.
For example, suppose you collect blood pressure data. A person in your sample has a systolic blood pressure of 95. This is a low value but reasonable. However, that same person has a diastolic blood pressure of 95. This is very unlikely to be correct. You would want to find the original data and try to confirm if this data point represents an error.
How data symmetry affects the sample mean and sample median
The sample mean and sample median are different when your data are not symmetrical. When data are nonsymmetrical, it is said to have a skewed distribution.
Consider three distributions: symmetrical, left-skewed, and right-skewed.
The histogram in Figure 4 below shows nearly symmetrical data. If you think about folding the plot in half in the middle, the two sides will be about the same. The mean and median are very similar.
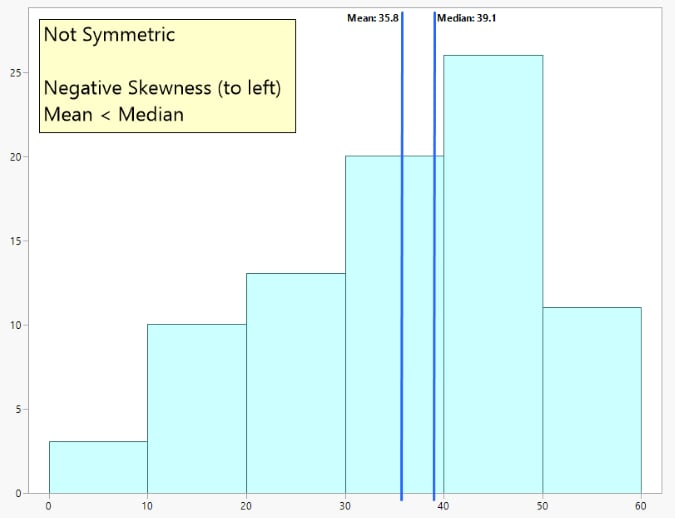
The histogram in Figure 5 shows data that is not symmetrical. This data is more heavily weighted to the lower values. It is skewed to the left. The skewness statistic is negative and the mean is less than the median.
The histogram in Figure 6 also shows data that is not symmetric. This data is more heavily weighted to the higher values. It is skewed to the right. The skewness statistic is positive and the mean is greater than the median.


When to use the mean and median
Figures 7-9 show the types of data for which the mean and median are appropriate to use.



Continuous data: mean and median are appropriate
The mean and median make sense for continuous data. These data are measured on a scale with many possible values. Some examples of continuous data are:
- Age
- Blood pressure
- Weight
- Temperature
- Speed
For all of these examples, it makes sense to calculate the mean and median.
Ordinal or nominal data: mean and median are not applicable
The mean and median do not make sense for ordinal or nominal data since these types of data are measured on a scale with only a few possible values.
With ordinal data, the sample is divided into groups, and the responses have a defined order. For example, in a survey where you are asked to give your opinion on a scale from “Strongly Disagree” to “Strongly Agree” (Figure 8), your responses are ordinal.
For nominal data, the sample is also divided into groups but there is no particular order. Two examples are biological sex and country of residence. In rare situations, when nominal data is coded with a numeric value, you can calculate means. The interpretation of the mean will depend on the coding. For example, if genders are coded using 0 for males and 1 for females and the sample average is calculated, you might obtain a value of 0.6. This value represents the proportion of females in your sample, which makes sense. For country, if you were to code the country name with numerical values, you could calculate a mean. However, it wouldn't make sense; the mean would have no meaningful interpretation.