One-Way ANOVA
What is one-way ANOVA?
One-way analysis of variance (ANOVA) is a statistical method for testing for differences in the means of three or more groups.
How is one-way ANOVA used?
One-way ANOVA is typically used when you have a single independent variable, or factor, and your goal is to investigate if variations, or different levels of that factor have a measurable effect on a dependent variable.
What are some limitations to consider?
One-way ANOVA can only be used when investigating a single factor and a single dependent variable. When comparing the means of three or more groups, it can tell us if at least one pair of means is significantly different, but it can’t tell us which pair. Also, it requires that the dependent variable be normally distributed in each of the groups and that the variability within groups is similar across groups.
One-way ANOVA is a test for differences in group means
See how to perform a one-way ANOVA using statistical software
- Download JMP to follow along using the sample data included with the software.
- To see more JMP tutorials, visit the JMP Learning Library.
One-way ANOVA is a statistical method to test the null hypothesis (H0) that three or more population means are equal vs. the alternative hypothesis (Ha) that at least one mean is different. Using the formal notation of statistical hypotheses, for k means we write:
$ H_0:\mu_1=\mu_2=\cdots=\mu_k $
$ H_a:\mathrm{not\mathrm{\ }all\ means\ are\ equal} $
where $\mu_i$ is the mean of the i-th level of the factor.
Okay, you might be thinking, but in what situations would I need to determine if the means of multiple populations are the same or different? A common scenario is you suspect that a particular independent process variable is a driver of an important result of that process. For example, you may have suspicions about how different production lots, operators or raw material batches are affecting the output (aka a quality measurement) of a production process.
To test your suspicion, you could run the process using three or more variations (aka levels) of this independent variable (aka factor), and then take a sample of observations from the results of each run. If you find differences when comparing the means from each group of observations using an ANOVA, then (assuming you’ve done everything correctly!) you have evidence that your suspicion was correct—the factor you investigated appears to play a role in the result!
A one-way ANOVA example
Let's work through a one-way ANOVA example in more detail. Imagine you work for a company that manufactures an adhesive gel that is sold in small jars. The viscosity of the gel is important: too thick and it becomes difficult to apply; too thin and its adhesiveness suffers. You've received some feedback from a few unhappy customers lately complaining that the viscosity of your adhesive is not as consistent as it used to be. You've been asked by your boss to investigate.
You decide that a good first step would be to examine the average viscosity of the five most recent production lots. If you find differences between lots, that would seem to confirm the issue is real. It might also help you begin to form hypotheses about factors that could cause inconsistencies between lots.
You measure viscosity using an instrument that rotates a spindle immersed in the jar of adhesive. This test yields a measurement called torque resistance. You test five jars selected randomly from each of the most recent five lots. You obtain the torque resistance measurement for each jar and plot the data.
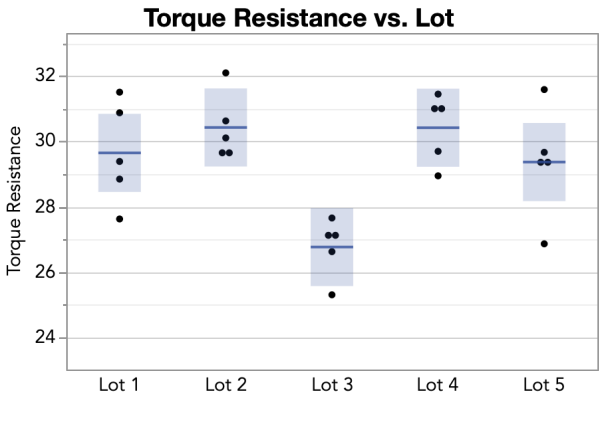
From the plot of the data, you observe that torque measurements from the Lot 3 jars tend to be lower than the torque measurements from the samples taken from the other lots. When you calculate the means from all your measurements, you see that the mean torque for Lot 3 is 26.77—much lower than the other four lots, each with a mean of around 30.
Table 1: Mean torque measurements from tests of five lots of adhesive
| Lot # | N | Mean |
|---|---|---|
| 1 | 5 | 29.65 |
| 2 | 5 | 30.43 |
| 3 | 5 | 26.77 |
| 4 | 5 | 30.42 |
| 5 | 5 | 29.37 |
The ANOVA table
ANOVA results are typically displayed in an ANOVA table. An ANOVA table includes:
- Source: the sources of variation including the factor being examined (in our case, lot), error and total.
- DF: degrees of freedom for each source of variation.
- Sum of Squares: sum of squares (SS) for each source of variation along with the total from all sources.
- Mean Square: sum of squares divided by its associated degrees of freedom.
- F Ratio: the mean square of the factor (lot) divided by the mean square of the error.
- Prob > F: the p-value.
Table 2: ANOVA table with results from our torque measurements
| Source | DF | Sum of Squares | Mean Square | F Ratio | Prob > F |
|---|---|---|---|---|---|
| Lot | 4 | 45.25 | 11.31 | 6.90 | 0.0012 |
| Error | 20 | 32.80 | 1.64 | ||
| Total | 24 | 78.05 |
We'll explain how the components of this table are derived below. One key element in this table to focus on for now is the p-value. The p-value is used to evaluate the validity of the null hypothesis that all the means are the same. In our example, the p-value (Prob > F) is 0.0012. This small p-value can be taken as evidence that the means are not all the same. Our samples provide evidence that there is a difference in the average torque resistance values between one or more of the five lots.
What is a p-value?
A p-value is a measure of probability used for hypothesis testing. The goal of hypothesis testing is to determine whether there is enough evidence to support a certain hypothesis about your data. Recall that with ANOVA, we formulate two hypotheses: the null hypothesis that all the means are equal and the alternative hypothesis that the means are not all equal.
Because we’re only examining random samples of data pulled from whole populations, there’s a risk that the means of our samples are not representative of the means of the full populations. The p-value gives us a way to quantify that risk. It is the probability that any variability in the means of your sample data is the result of pure chance; more specifically, it’s the probability of observing variances in the sample means at least as large as what you’ve measured when in fact the null hypothesis is true (the full population means are, in fact, equal).
A small p-value would lead you to reject the null hypothesis. A typical threshold for rejection of a null hypothesis is 0.05. That is, if you have a p-value less than 0.05, you would reject the null hypothesis in favor of the alternative hypothesis that at least one mean is different from the rest.
Based on these results, you decide to hold Lot 3 for further testing. In your report you might write: The torque from five jars of product were measured from each of the five most recent production lots. An ANOVA analysis found that the observations support a difference in mean torque between lots (p = 0.0012). A plot of the data shows that Lot 3 had a lower mean (26.77) torque as compared to the other four lots. We will hold Lot 3 for further evaluation.
Remember, an ANOVA test will not tell you which mean or means differs from the others, and (unlike our example) this isn't always obvious from a plot of the data. One way to answer questions about specific types of differences is to use a multiple comparison test. For example, to compare group means to the overall mean, you can use analysis of means (ANOM). To compare individual pairs of means, you can use the Tukey-Kramer multiple comparison test.
One-way ANOVA calculation
Now let’s consider our torque measurement example in more detail. Recall that we had five lots of material. From each lot we randomly selected five jars for testing. This is called a one-factor design. The one factor, lot, has five levels. Each level is replicated (tested) five times. The results of the testing are listed below.
Table 3: Torque measurements by Lot
| Lot 1 | Lot 2 | Lot 3 | Lot 4 | Lot 5 | |
|---|---|---|---|---|---|
| Jar 1 | 29.39 | 30.63 | 27.16 | 31.03 | 29.67 |
| Jar 2 | 31.51 | 32.10 | 26.63 | 30.98 | 29.32 |
| Jar 3 | 30.88 | 30.11 | 25.31 | 28.95 | 26.87 |
| Jar 4 | 27.63 | 29.63 | 27.66 | 31.45 | 31.59 |
| Jar 5 | 28.85 | 29.68 | 27.10 | 29.70 | 29.41 |
| Mean | 29.65 | 30.43 | 26.77 | 30.42 | 29.37 |
To explore the calculations that resulted in the ANOVA table above (Table 2), let's first establish the following definitions:
$n_i$ = Number of observations for treatment $i$ (in our example, Lot $i$)
$N$ = Total number of observations
$Y_{ij}$ = The jth observation on the ith treatment
$\overline{Y}_i$ = The sample mean for the ith treatment
$\overline{\overline{Y}}$ = The mean of all observations (grand mean)
Sum of Squares
With these definitions in mind, let's tackle the Sum of Squares column from the ANOVA table. The sum of squares gives us a way to quantify variability in a data set by focusing on the difference between each data point and the mean of all data points in that data set. The formula below partitions the overall variability into two parts: the variability due to the model or the factor levels, and the variability due to random error.
$$ \sum_{i=1}^{a}\sum_{j=1}^{n_i}(Y_{ij}-\overline{\overline{Y}})^2\;=\;\sum_{i=1}^{a}n_i(\overline{Y}_i-\overline{\overline{Y}})^2+\sum_{i=1}^{a}\sum_{j=1}^{n_i}(Y_{ij}-\overline{Y}_i)^2 $$
$$ SS(Total)\; = \;SS(Factor)\; + \;SS(Error) $$
While that equation may seem complicated, focusing on each element individually makes it much easier to grasp. Table 4 below lists each component of the formula and then builds them into the squared terms that make up the sum of squares. The first column of data ($Y_{ij}$) contains the torque measurements we gathered in Table 3 above.
Another way to look at sources of variability: between group variation and within group variation
Recall that in our ANOVA table above (Table 2), the Source column lists two sources of variation: factor (in our example, lot) and error. Another way to think of those two sources is between group variation (which corresponds to variation due to the factor or treatment) and within group variation (which corresponds to variation due to chance or error). So using that terminology, our sum of squares formula is essentially calculating the sum of variation due to differences between the groups (the treatment effect) and variation due to differences within each group (unexplained differences due to chance).
Table 4: Sum of squares calculation
| Lot | $Y_{ij} $ | $\overline{Y}_i $ | $\overline{\overline{Y}}$ | $\overline{Y}_i-\overline{\overline{Y}}$ | $Y_{ij}-\overline{\overline{Y}}$ | $Y_{ij}-\overline{Y}_i $ | $(\overline{Y}_i-\overline{\overline{Y}})^2 $ | $(Y_{ij}-\overline{Y}_i)^2 $ | $(Y_{ij}-\overline{\overline{Y}})^2 $ |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 29.39 | 29.65 | 29.33 | 0.32 | 0.06 | -0.26 | 0.10 | 0.07 | 0.00 |
| 1 | 31.51 | 29.65 | 29.33 | 0.32 | 2.18 | 1.86 | 0.10 | 3.46 | 4.75 |
| 1 | 30.88 | 29.65 | 29.33 | 0.32 | 1.55 | 1.23 | 0.10 | 1.51 | 2.40 |
| 1 | 27.63 | 29.65 | 29.33 | 0.32 | -1.70 | -2.02 | 0.10 | 4.08 | 2.89 |
| 1 | 28.85 | 29.65 | 29.33 | 0.32 | -0.48 | -0.80 | 0.10 | 0.64 | 0.23 |
| 2 | 30.63 | 30.43 | 29.33 | 1.10 | 1.30 | 0.20 | 1.21 | 0.04 | 1.69 |
| 2 | 32.10 | 30.43 | 29.33 | 1.10 | 2.77 | 1.67 | 1.21 | 2.79 | 7.68 |
| 2 | 30.11 | 30.43 | 29.33 | 1.10 | 0.78 | -0.32 | 1.21 | 0.10 | 0.61 |
| 2 | 29.63 | 30.43 | 29.33 | 1.10 | 0.30 | -0.80 | 1.21 | 0.64 | 0.09 |
| 2 | 29.68 | 30.43 | 29.33 | 1.10 | 0.35 | -0.75 | 1.21 | 0.56 | 0.12 |
| 3 | 27.16 | 26.77 | 29.33 | -2.56 | -2.17 | 0.39 | 6.55 | 0.15 | 4.71 |
| 3 | 26.63 | 26.77 | 29.33 | -2.56 | -2.70 | -0.14 | 6.55 | 0.02 | 7.29 |
| 3 | 25.31 | 26.77 | 29.33 | -2.56 | -4.02 | -1.46 | 6.55 | 2.14 | 16.16 |
| 3 | 27.66 | 26.77 | 29.33 | -2.56 | -1.67 | 0.89 | 6.55 | 0.79 | 2.79 |
| 3 | 27.10 | 26.77 | 29.33 | -2.56 | -2.23 | 0.33 | 6.55 | 0.11 | 4.97 |
| 4 | 31.03 | 30.42 | 29.33 | 1.09 | 1.70 | 0.61 | 1.19 | 0.37 | 2.89 |
| 4 | 30.98 | 30.42 | 29.33 | 1.09 | 1.65 | 0.56 | 1.19 | 0.31 | 2.72 |
| 4 | 28.95 | 30.42 | 29.33 | 1.09 | -0.38 | -1.47 | 1.19 | 2.16 | 0.14 |
| 4 | 31.45 | 30.42 | 29.33 | 1.09 | 2.12 | 1.03 | 1.19 | 1.06 | 4.49 |
| 4 | 29.70 | 30.42 | 29.33 | 1.09 | 0.37 | -0.72 | 1.19 | 0.52 | 0.14 |
| 5 | 29.67 | 29.37 | 29.33 | 0.04 | 0.34 | 0.30 | 0.00 | 0.09 | 0.12 |
| 5 | 29.32 | 29.37 | 29.33 | 0.04 | -0.01 | -0.05 | 0.00 | 0.00 | 0.00 |
| 5 | 26.87 | 29.37 | 29.33 | 0.04 | -2.46 | -2.50 | 0.00 | 6.26 | 6.05 |
| 5 | 31.59 | 29.37 | 29.33 | 0.04 | 2.26 | 2.22 | 0.00 | 4.93 | 5.11 |
| 5 | 29.41 | 29.37 | 29.33 | 0.04 | 0.08 | 0.04 | 0.00 | 0.00 | 0.01 |
| Sum of Squares | SS (Factor) = 45.25 | SS (Error) = 32.80 | SS (Total) = 78.05 |
Degrees of Freedom (DF)
Associated with each sum of squares is a quantity called degrees of freedom (DF). The degrees of freedom indicate the number of independent pieces of information used to calculate each sum of squares. For a one factor design with a factor at k levels (five lots in our example) and a total of N observations (five jars per lot for a total of 25), the degrees of freedom are as follows:
Table 5: Determining degrees of freedom
| Degrees of Freedom (DF) Formula | Calculated Degrees of Freedom | |
|---|---|---|
| SS (Factor) | k - 1 | 5 - 1 = 4 |
| SS (Error) | N - k | 25 - 5 = 20 |
| SS (Total) | N - 1 | 25 - 1 = 24 |
Mean Squares (MS) and F Ratio
We divide each sum of squares by the corresponding degrees of freedom to obtain mean squares. When the null hypothesis is true (i.e. the means are equal), MS (Factor) and MS (Error) are both estimates of error variance and would be about the same size. Their ratio, or the F ratio, would be close to one. When the null hypothesis is not true then the MS (Factor) will be larger than MS (Error) and their ratio greater than 1. In our adhesive testing example, the computed F ratio, 6.90, presents significant evidence against the null hypothesis that the means are equal.
Table 6: Calculating mean squares and F ratio
| Sum of Squares (SS) | Degrees of Freedom (DF) | Mean Squares | F Ratio | |
|---|---|---|---|---|
| SS (Factor) | 45.25 | 4 | 45.25/4 = 11.31 | 11.31/1.64 = 6.90 |
| SS (Error) | 32.80 | 20 | 32.80/20 = 1.64 |
The ratio of MS(factor) to MS(error)—the F ratio—has an F distribution. The F distribution is the distribution of F values that we'd expect to observe when the null hypothesis is true (i.e. the means are equal). F distributions have different shapes based on two parameters, called the numerator and denominator degrees of freedom. For an ANOVA test, the numerator is the MS(factor), so the degrees of freedom are those associated with the MS(factor). The denominator is the MS(error), so the denominator degrees of freedom are those associated with the MS(error).
If your computed F ratio exceeds the expected value from the corresponding F distribution, then, assuming a sufficiently small p-value, you would reject the null hypothesis that the means are equal. The p-value in this case is the probability of observing a value greater than the F ratio from the F distribution when in fact the null hypothesis is true.