Perfect Scheduled Attendance
This report compares the distribution of study visit days for each center compared to all other centers combined, and identifies unusual differences. For example, a site where all visits occur on the same study day can be flagged for further investigation.
Report Results Description
Running this report with the Nicardipine sample setting and default options generates the output shown below.
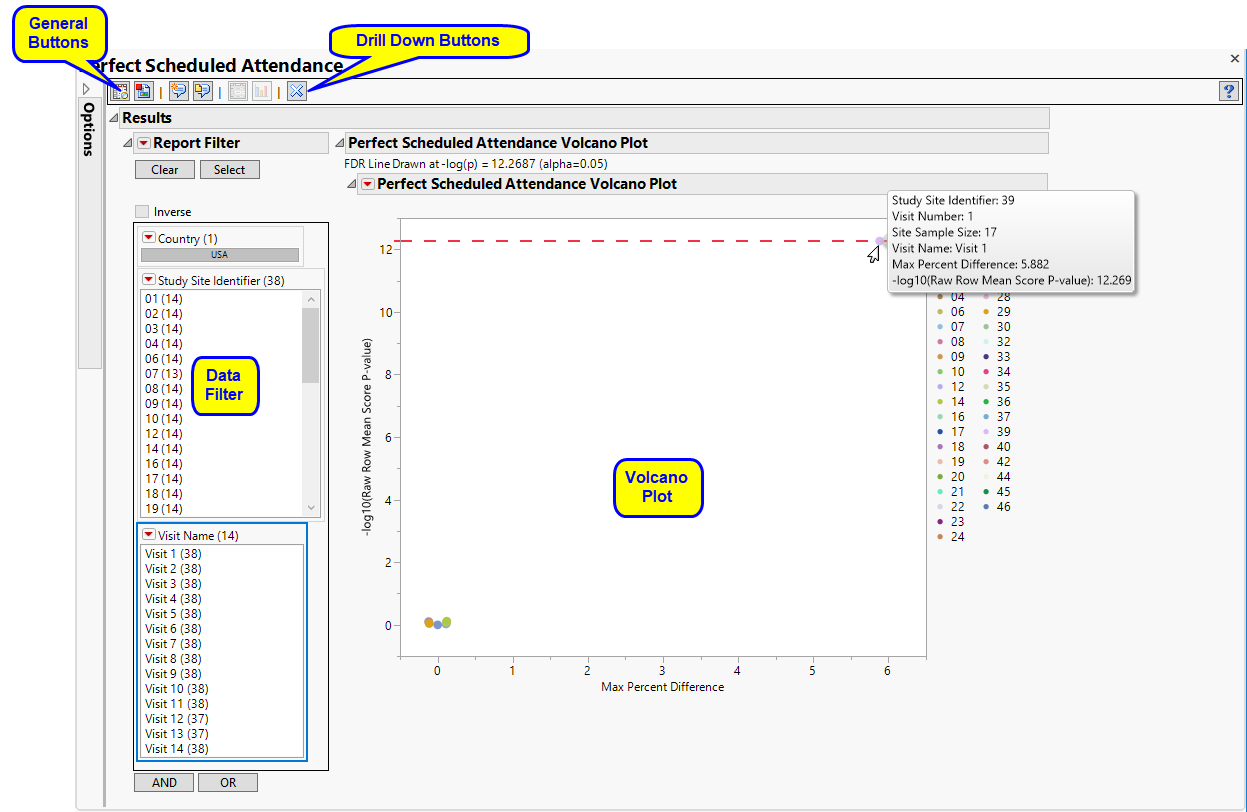
The Perfect Scheduled Attendance report initially shows one Volcano Plot
Each point represents the comparison of a site to all other sites. This comparison is used to determine whether there is a difference in distribution for perfect attendance and is done for all sites across all tests in all findings domains.
The Y axis is the -log10(Row Mean Score p-value). Large numbers indicate statistically significant results.
The X axis is the maximum percent difference across all visits between a site versus all sites.
Values far from 0 indicate important differences between a site and the reference distribution of all other sites. An FDR line is indicated by the dotted red line. Values above this line (Such as site 39, above) can be considered significant adjusting for multiple comparisons. This could identify rounding issues or other problems with how a site reports a particular test compared to other sites.
Note: In the example shown above, the vast majority of the study sites (circled above) show little or no differences in Perfect attendance. In fact, the points representing these sites overlap such that individual sites cannot be differentiated at this scale.
You can use the available options to drill-down into the data
Action Buttons
Action buttons, provide you with an easy way to drill down into your data. Use your mouse to select one or more sites of interest (as shown for site 39, above) , as shown below, before clicking one of the action buttons:
The following action buttons are available:
| • | Show Sites: Shows the rows of the data table for the selected points from the volcano plot. |
Clicking  opens the following table:
opens the following table:

In this example, only site 39 showed a near perfect attendance and only for Visit 1.
| • | Visit Bar Charts: For the points selected in the volcano plot, clicking  displays a bar chartcomparing the percent of subjects with perfect attendance between selected sites versus all others. This gives the user the ability to compare just how different each site is scheduled attendance. The underlying data table is available by going to Script > Data Table . The following chart shows the sites/tests selected above: displays a bar chartcomparing the percent of subjects with perfect attendance between selected sites versus all others. This gives the user the ability to compare just how different each site is scheduled attendance. The underlying data table is available by going to Script > Data Table . The following chart shows the sites/tests selected above: |

Data Filter
This enables you to subset your data based on study site and/or visit number. Refer to Data Filter for more information about how to use the Data Filter.
General
| • | Click  to view the associated data tables. Refer to Show Tables/View Data for more information. to view the associated data tables. Refer to Show Tables/View Data for more information. |
| • | Click  to generate a standardized pdf- or rtf-formatted report containing the plots and charts of selected sections. to generate a standardized pdf- or rtf-formatted report containing the plots and charts of selected sections. |
| • | Click  to generate a JMP Live report. Refer to Create Live Report for more information. to generate a JMP Live report. Refer to Create Live Report for more information. |
| • | Click  to take notes, and store them in a central location. Refer to Add Notes for more information. to take notes, and store them in a central location. Refer to Add Notes for more information. |
| • | Click  to read user-generated notes. Refer to View Notes for more information. to read user-generated notes. Refer to View Notes for more information. |
| • | Click  to open and view the Review Subject Filter. to open and view the Review Subject Filter. |
| • | Click  to specify Derived Population Flags that enable you to divided the subject population into two distinct groups based on whether they meet very specific criteria. to specify Derived Population Flags that enable you to divided the subject population into two distinct groups based on whether they meet very specific criteria. |
| • | Click the arrow to reopen the completed report dialog used to generate this output. |
| • | Click the gray border to the left of the Options tab to open a dynamic report navigator that lists all of the reports in the review. Refer to Report Navigator for more information. |
Methodology
This report compares the observed distribution of study day for each visit with each site compared to all other sites taken together as a reference. The comparison is made using a row mean score chi-square tests as described for Digit Preference, with study day replacing digit as the column variable.
Alternatively, exact Mantel-Haenszel p-values can be computed. The Mantel-Haenszel chi-square statistic tests the alternative hypothesis that there is a linear association between the row variable and the column variable. Both variables must lie on an ordinal scale. The Mantel-Haenszel chi-square statistic is computed as (n-1)r^2 where r is the Pearson correlation between the row variable and the column variable. 5000 samples (default) are used to compute resampling p-value, which is the proportion of resampled values that are more extreme the observed p-value.
FDR p-values are calculated and the reference line is determined as described in How does JMP Clinical calculate the False Discovery Rate (FDR)?.
Report Options
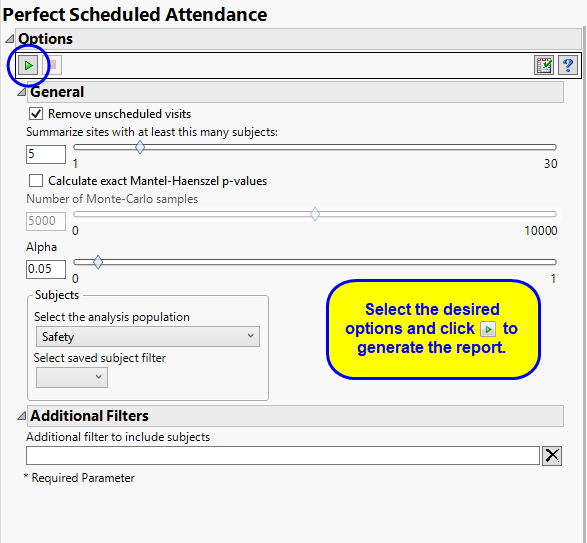
Unscheduled Visits
Unscheduled visits can occur for a variety of reasons and can complicate analyses. By default, these are excluded from this analysis. However, by unchecking the Remove unscheduled visits box, you have the option of including them.
Analysis
The Summarize sites with at least this many subjects: option enables you to set a minimal threshold for the sites to be analyzed. Only those sites which exceed the specified number of subjects are included. This feature is useful because it enables you to exclude smaller sites, where small differences due to random events are more likely to appear more significant than they truly are. In larger sites, observed differences from expected attendance due to random events are more likely to be significant because any deviations due to random events are less likely to be observed.
Use the Calculate exact Mantel-Haenszel p-values option computes exact p-values using permutation distributions on stratified groupings of the responses. They can often be more accurate and reliable. If you are unsure if this method is appropriate, try it and compare the results with those from the default method. Agreement between the methods gives some assurance that they are robust. If they do not agree, you should explore your data further to identify the cause of discrepancies. Check frequencies, counts, and cross-tabulations.
The Number of Monte-Carlo Samples option enables you to specify the number of simulated samples you want to generate. In general, the more samples you take, the more robust your conclusions. However, increasing the number of samples can greatly increase the time needed to run the analysis. You should experiment with this option to find the right balance for your needs. One common approach is to begin with a small size and gradually increase it until results stabilize.
The Alpha option is used to specify the significance level by which to judge the validity of the statistics generated by this report. By definition, alpha represents the probability that you will reject the null hypothesis when the null is, in fact, true. Alpha can be set to any number between 0 and 1, but is most typically set at 0.01, 0.05, or 0.10. The higher the alpha, the lower your confidence that the results you observe are correct.
Filtering the Data:
Filters enable you to restrict the analysis to a specific subset of subjects based on values within variables. You can also filter based on population flags (Safety is selected by default) within the study data.
See Select the analysis population, Select saved subject filter1, Additional Filter to Include Subjects, and Subset of Visits to Analyze for Findings for more information.