 「K近傍法」プラットフォームの起動
「K近傍法」プラットフォームの起動
「K近傍法」プラットフォームを起動するには、[分析]>[予測モデル]>[K近傍法]を選択します。
図7.4 「K近傍法」の起動ウィンドウ
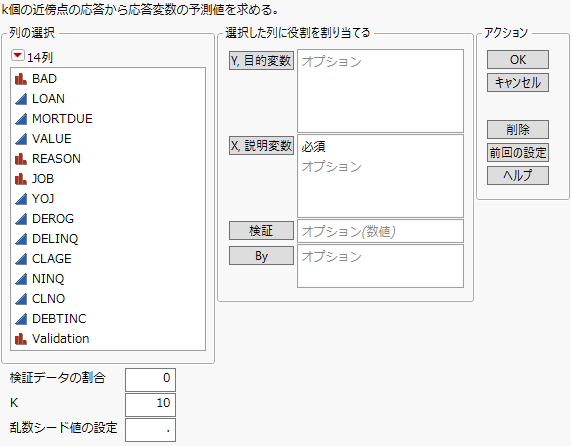
「列の選択」の赤い三角ボタンのメニューにあるオプションの詳細については、『JMPの使用法』の列フィルタメニューを参照してください。
「K近傍法」の起動ウィンドウには、以下のオプションがあります。
Y, 目的変数
分析したい目的変数(応答変数)。
注: 「K近傍法」プラットフォームは、たとえ応答変数がない場合でも、隣り合う測定値間の距離を判断するためのユーティリティとして使用できます。応答変数を指定しなかった場合は、空白のレポートが表示されます。ただし、赤い三角ボタンのメニューにある[近傍行の保存]や[近傍距離の保存]のオプションは使用できます。
X, 説明変数
モデルに含める説明変数。
検証
多くとも3つの数値を含む数値列。検証を参照してください。
By
別々に分析を行いたいときに、そのグループ分けをする変数を指定します。指定された列の水準ごとに、別々に分析が行われます。各水準の結果は別々のレポートに表示されます。複数のBy変数を割り当てた場合、それらのBy変数の水準の組み合わせごとに別々のレポートが作成されます。
検証データの割合
データ全体のうち検証に用いるデータの割合です。検証を参照してください。
近傍点の個数, K
近傍点の最大数。1個の近傍点から、Kに指定した個数の近傍点までのモデルがあてはめられます。
注: 近傍点の最大数Kは、学習データテーブルの行数から1を引いた値以下でなければなりません。許容される最大数Kより大きな値をKに指定した場合は、警告が表示されます。
乱数シード値の設定
応答変数が名義尺度や順序尺度の場合で、近傍にあるカテゴリの個数が同数のときには、乱数によってそれらのうちのいずれかのカテゴリに分類されます。そのときに用いる乱数のシード値を設定します。検証データの割合を指定する場合、このオプションは検証に使用される行を決める乱数のシード値も設定します。乱数シード値の設定は、ある分析を再現したい場合に役立ちます。乱数シード値を設定してスクリプトを保存する場合、シード値はスクリプト内に自動的に保存されます。