「工程履歴エクスプローラ」プラットフォームのオプション
「工程履歴エクスプローラ」の赤い三角ボタンをクリックすると、以下のオプションが表示されます。
収率が低い水準
各[X, 工程]変数の各水準における歩留まりに関する要約統計量の表を表示します。各水準に対する要約統計量は、操作回数(度数)と、歩留まりの平均・標準誤差・標準偏差です。デフォルトでは、この要約統計量の表は、歩留まりの平均によって昇順で並べ替えられています。
収率が低い水準と時間区間
歩留まりが最も低くなっている上位50水準の水準ごとに、歩留まりが低くなっている期間を探し出し、その要約統計量の表を表示します。この計算では歩留まりが最も低くなっている水準の上位50水準ごとに、時間でフィルタリングします。そして、時間平均歩留まりが最小化となるような期間を探し出します。この期間には、その水準における測定値数の少なくとも25%が含まれている必要があります。各水準に提供される要約統計量は、探し出された期間での測定値数(度数)、探し出された期間での平均収率、各工程の最も早い時点と最も時点(最初の時点と最後の時点 )、探し出された期間の長さ、その期間の開始時点と終了時点(開始時点と終了時点)です。
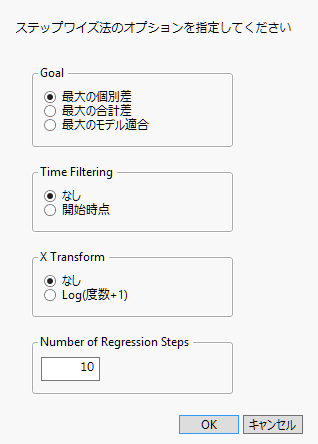
ステップワイズ回帰
変数選択を行うための「ステップワイズ回帰」ウィンドウを表示します。このウィンドウでは、ステップワイズ回帰に対するオプションを指定できます。ステップワイズ回帰を使用して工程の問題を発見することができます。つまり、歩留まりを下げる原因を発見することができます。ステップワイズ回帰の各ステップで、歩留まりを低くしている項に応じて、最低となっている項をモデルに追加していきます。ステップワイズ回帰は、歩留まりに最も影響を与える工程を特定するのに役立ちます。ステップワイズ回帰のレポートには、回帰の各ステップでモデルに追加されていった項の順序を示す表があります。
注: なお、起動ウィンドウで[目標は最小化]オプションが選択されていた場合、歩留まりが大きくする項を検知するようにステップワイズ回帰が行われます。
基準
ステップワイズ回帰モデルで使用する基準を指定します。[1ユニットあたりの差を最大化]オプションは、1つのユニットに関して歩留まりを最も変化させる条件を特定します。[差の合計を最大化]オプションは、同一条件に属するユニットで差の合計において、歩留まりを最も変化させる条件を特定します。このときの基準は、モデルで求められた差に、該当の工程に属するユニット数を掛けたものです。[モデル適合度を最適化]オプションは、従来のステップワイズ法を行います。
期間フィルタ
ステップワイズ回帰モデルで工程の開始時刻を使用できます。[None]オプションを選択すると、全期間にわたって平均化されます。[開始時刻]オプションを選択すると、データが特定の開始時刻で除外されます。この開始時点は、歩留まりに対する悪い影響が最大化される時点です。[開始時刻]オプションを選択すると、「ステップワイズ回帰」レポートの表には、「開始時刻」列が含まれます。
X変数の変換
ステップワイズ回帰の[X, 工程]変数として、通常の度数を用いるか、またはLog(度数 + 1)を用いるかを指定します。[Log(度数 + 1)]オプションを選択した場合、度数の多いデータが結果に与える影響が小さくなります。[なし]オプションを選択した場合、度数の増加による結果への影響は線形になります。
ステップワイズ回帰のステップ数
ステップワイズ法での最大ステップ数。デフォルトでは10ステップになっています。
図25.4 「ステップワイズ回帰」ウィンドウ
待ち時間分析
(タイムスタンプ変数が2つ指定されているときだけ使用可能。)一意なIDで示される1つの要素は、[段階]列で示されるある1つの段階を1回しか通過できません。さらに、各段階は、一意なIDで示される1つの要素しか処理できません。待ち時間分析では、各IDの待ち時間に関する表を作成します。この表では、IDで示される特定の要素に、ある処理が行われてからを別の処理が行われるまでの時間です。待ち時間分析の表は複数あります。各[段階]変数の水準内の各IDに対しても、表が作成されます。これらの追加の表で、待ち時間とは、[段階]変数の特定の水準において、IDで示される特定の要素に、ある処理が行われてから別の処理が行われるまでの時間です。この表では、次の要約統計量が得られます。
待ち時間の合計
[ID]と[段階]の組み合わせごとに計算された、待ち時間の合計。
待機の回数
[ID]と[段階]の組み合わせごとの、待ち状態が生じる回数。
待ち時間の平均
[ID]と[段階]の組み合わせごとに計算された、待ち時間の平均。
待ち時間の最大値
[ID]と[段階]の組み合わせごとに計算された、最長待ち時間。
遷移分析
ある工程からから別の工程への遷移のなかで、問題がある遷移を特定するのに役立つレポートを表示します。このレポートは、工程の配置や順序によって生じる問題を特定するのに役立ちます。たとえば、いくつかの工程においては、他の工程と組み合わせたときに歩留まりが悪くなっているかもしれません。また、別の工程を通ってきたユニットは、同じ工程を繰り返したユニットよりも歩留まりが悪くなっているかもしれません。
このオプションを選択するときは、1つ以上の[X, 工程]列を指定し、かつ、指定した各X列で1つ以上の水準を選択する必要があります。指定したX列ごとに、4つの表が表示されます。1番目の表は、列の特定の水準から別の特定の水準へ遷移しているユニットの歩留まりと度数を示しています。2番目の表は、列の特定の水準から遷移しているユニットの歩留まりと度数を示しています。3番目の表は、列の特定の水準へと遷移しているユニットの歩留まりと度数を示しています。4番目の表は、特定の同じ水準で遷移しているユニットの歩留まりと度数を示しています。
順序の交互作用
(起動ウィンドウで[順序]列が指定されている場合だけ利用可能。)各X列の各水準ごとに行った、[順序]列を因子とした一元配置分散分析の検定結果が表示されます。[X, 工程]列ごとにレポートが表示されます。それぞれの表で、[X, 工程]列の水準は、対応する一元配置分散分析モデルにおける対数価値(LogWorth)の降順で並べ替えられています。表には、ヒートマップとp値も含まれています。
度数テーブルの保存
[X, 工程]変数の各水準を通過したユニット数を含む新しいデータテーブルを作成します。この度数テーブルの各行は、ID値で決定される一意のユニットになっています。
対数度数テーブルの保存
度数テーブルと同じデータ形式ですが、データ値がLog(度数 + 1)となっている新しいデータテーブルを作成します。
待ち時間の保存
(2つのタイムスタンプ変数が指定されている場合のみ使用可能。)「待ち時間分析」レポートの各表を別々のデータテーブルに保存します。