이 예에서는 제약 및 컴퓨터 업계의 32개 회사에 대한 재무 데이터가 포함된 Companies.jmp 데이터 테이블을 사용합니다.
|
1.
|
도움말 > 샘플 데이터 라이브러리를 선택하고 Companies.jmp를 엽니다.
|
|
2.
|
Companies.jmp 샘플 데이터 테이블을 열어 둔 상태라면 제외되었거나 숨겨진 행이 있을 수 있습니다. 행을 기본 상태로 되돌려 숨겨진 행 없이 모든 행을 포함하려면 행 > 행 상태 지우기를 선택합니다.
|
|
3.
|
분석 > X로 Y 적합을 선택합니다.
|
|
4.
|
Profits ($M)를 선택하고 Y, 반응을 클릭합니다.
|
|
5.
|
Type을 선택하고 X, 요인을 클릭합니다.
|
|
6.
|
확인을 클릭합니다.
|

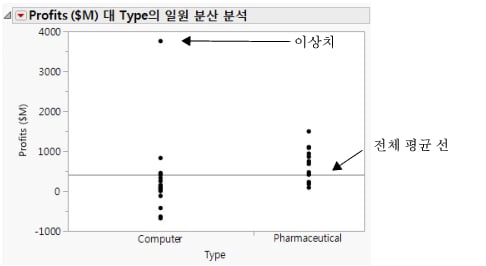
|
1.
|
|
2.
|
행 > 제외/제외 해제를 선택합니다. 해당 데이터 점이 더 이상 계산에 포함되지 않습니다.
|
|
3.
|
행 > 숨기기/숨기기 해제를 선택합니다. 해당 데이터 점이 모든 그래프에서 숨겨집니다.
|
|
4.
|
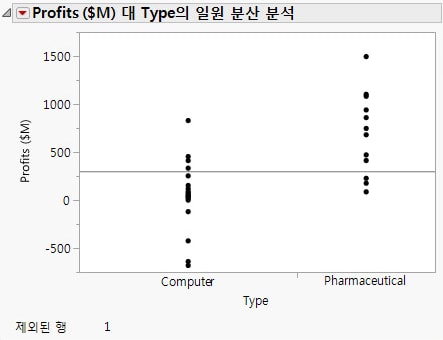
|
–
|
표시 옵션 > 평균 선. 이 옵션을 선택하면 산점도에 평균 선이 추가됩니다.
|
|
–
|
평균 및 표준편차. 이 옵션을 선택하면 평균 및 표준편차를 제공하는 보고서가 표시됩니다.
|
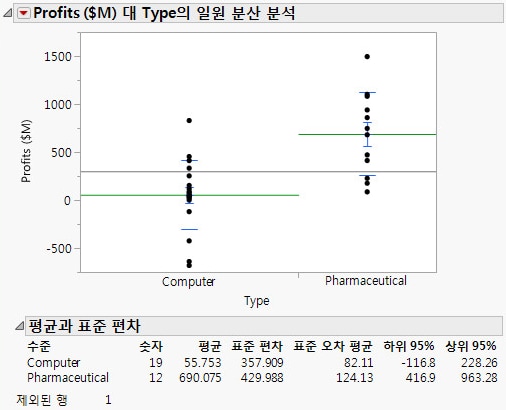
t-검정을 수행하려면 일원 분산 분석의 빨간색 삼각형에서 평균/분산 분석/합동 t를 선택합니다.

신뢰 구간 한계를 사용하여 두 회사 유형의 수익에 얼마나 많은 차이가 있는지 파악합니다. t-검정 결과에서 신뢰 구간 상한 차이 및 신뢰 구간 하한 차이를 살펴봅니다. 재무 분석가는 제약 회사의 평균 수익이 컴퓨터 회사의 평균 수익보다 높은 3억 4천 3백만 달러에서 9억 2천 6백만 달러 사이라고 결론을 내립니다.