“收益矩阵”报表和“决策矩阵”报表的示例
在该示例中,考察肝癌患者的一个研究。基于各种测量值和标志物,您想要根据患者的疾病严重程度(高或低)对患者进行分类。为患者分类时存在两类错误:将严重程度高的对象划分到低组,或将严重程度低的对象划分到高组。临床上,将严重程度高的患者错误划分到低组是代价很高的错误,因为患者可能无法获得所需的积极治疗。将严重程度低的患者划分到严重程度高的组是一个代价相对较低的错误。该患者可能获得比所需治疗更积极的治疗,但是这问题不大。
在下例中,您以肝癌研究为背景定义了收益矩阵,得到“决策矩阵”报表。“决策矩阵”报表可帮助您评估相对于您在收益矩阵中所指定的成本的分类率。
1. 选择帮助 > 样本数据库,然后打开 Liver Cancer.jmp。
2. 选择分析 > 预测建模 > 分割。
3. 选择严重性并点击 Y,响应。
4. 从 BMI 一直选到黄疸,然后点击 X,因子。
5. 基于您的 JMP 安装选择一个验证过程:
‒ 对于 JMP Pro,选择验证并点击验证。
‒ 对于 JMP,输入 0.3 作为验证比例。
注意:因为验证行是随机选择的,使用验证比例的结果可能不同于此处所示的结果。
图 4.25 验证部分 = 0.3 的已完成启动窗口
6. 点击确定。
7. 按住 Shift 键并点击拆分。
8. 为拆分数输入 10,然后点击确定。
确认图下方的面板中显示的“拆分数”为 10。
9. 点击“‘严重性’分割”旁边的红色小三角菜单,选择指定收益矩阵。
10. 按下图所示更改条目:
‒ 在“High,High”框中输入 1。
‒ 在“High,Low”框中输入 -5。
‒ 在“Low,High”框中输入 -3。
‒ 在“Low,Low”框中输入 1。
图 4.26 完成的收益矩阵

提示:您可以将该收益矩阵另存为列属性,以供将来分析时使用。选中“收益矩阵”窗口底部的“保存为列属性”复选框。
请注意以下事项:
‒ 值 1 反映您作出正确决策时所得到的收益。
‒ -3 值表示若您将严重性为“Low”的患者分类为严重性“High”,您的损失是正确决策收益的 3 倍。
‒ -5 值指示若您将严重性为“High”的患者分类为严重性“Low”,您的损失是正确决策收益的 5 倍。
11. 点击确定。
12. 点击“‘严重性’分割”旁边的红色小三角菜单,选择显示拟合详细信息。
图 4.27 “混淆矩阵”报表和“决策矩阵”报表
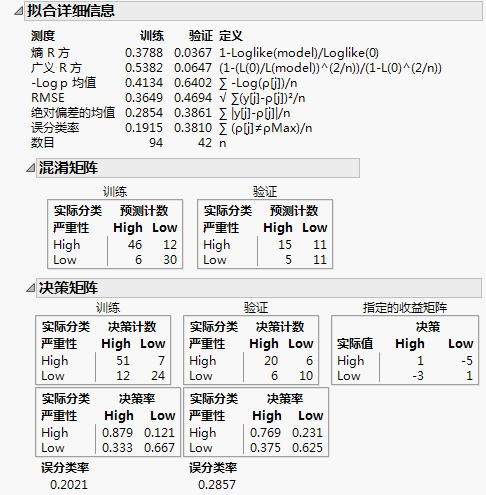
“混淆矩阵”报表和“决策矩阵”报表位于“拟合详细信息”报表中的“测度”列表的后面。注意到“混淆矩阵”报表和“决策矩阵”报表中的混淆矩阵显示不同的计数。这是因为与不带权重的预测概率相比,收益矩阵中的权重会生成不同的决策。
验证集的混淆矩阵基于预测概率单独显示分类。基于这些概率可以看出,11 个“High”严重性的患者被分类为“Low”严重性,5 个“Low”严重性的患者被分类为“High”严重性。
“决策矩阵”报表包含收益矩阵权重。使用这些权重,只有 6 个“High”严重性的患者被分类为“Low”严重性。不过,这样做的代价是有 6 个“Low”严重性的患者被误分类到“High”严重性组(1 个另外的患者)。
13. 点击“‘严重性’分割”旁边的红色小三角菜单,选择保存列 > 保存预测公式。
数据表中添加了八列。
提示:要快速返回数据表,请点击报表窗口 (Windows) 右下角的“查看相关的数据”图标 ![]() ,或是工具栏菜单 (macOS) 上的“显示数据表”图标。
,或是工具栏菜单 (macOS) 上的“显示数据表”图标。
‒ 前三列仅涉及预测概率。混淆矩阵计数基于最可能的“严重性”列,该列将患者分类到预测概率最高的那个水平。预测概率在 Prob(严重性==High) 和 Prob(严重性==Low) 列中给出。
‒ 后五列涉及收益矩阵权重。名为“严重性”的最佳收益预测的列包含基于收益矩阵所作的决策。针对患者所作的决策是具有最大收益的那个水平。收益在“High”的收益和“Low”的收益列中给出。