 “模型启动”控制面板
“模型启动”控制面板
当您在启动窗口中点击“确定”时,会出现“支持向量机”报表窗口,该窗口显示用于拟合模型的“模型启动”控制面板。使用“模型启动”控制面板指定核函数和相关参数值以及验证方法。
图 9.5 “模型启动”控制面板
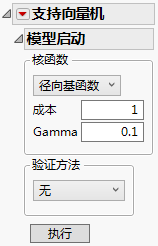
“模型启动”控制面板包含以下选项:
核函数
指定模型中使用的核函数。从以下核函数中进行选择:
径向基函数
选择径向基函数内核,以创建用于分离各个类的非线性超平面。
‒ 成本参数是与误分类观测关联的罚值。较高的成本参数实现的算法不太可能误分类某个点,而较低的成本参数实现的算法更灵活。成本参数必须大于 0,且默认值为 1。
‒ Gamma 参数是核函数中的参数。该参数确定决策线的曲率;Gamma 值越高,表示曲率越大。非线性决策线提供了更灵活的拟合,但曲率过大会导致过度拟合。Gamma 参数必须大于 0,且默认值为 1/(预测变量数)。
线性
选择线性核函数以创建用于分离各个类的线性超平面。
‒ 成本参数是与误分类观测关联的罚值。较高的成本参数实现的算法不太可能误分类某个点,而较低的成本参数实现的算法更灵活。成本参数必须大于 0,且默认值为 1。
注意:若指定的参数值超出范围,则使用默认值。
提示:要查找最佳拟合模型,需拟合一系列核函数和参数值并使用“模型比较”报表。
验证方法
指定模型验证方法。首次点击执行按钮后,将使用指定的验证方法拟合第一个 SVM 模型。“验证方法”随后用于 SVM 窗口内的所有 SVM 模型拟合。这样可以确保报表窗口中的所有模型都使用相同的验证方法和验证集进行拟合。
保留
将原始数据随机划分为训练集和验证集。您可以指定要用作验证集(保留)的数据占原始数据的比例。
K 重
(仅当 Y 恰好有两个水平时才可用。)将原始数据随机划分为 K 个子集。这 K 个子集依次对基于剩余 k-1 个子集的数据构建的模型进行验证,总共拟合 K 个模型。具有最佳验证统计量的模型将被选为最终模型。
验证列
(仅当在启动窗口中指定了验证列时才可用。)使用指定的验证列中的值将数据分成多个部分。该列的值决定如何拆分数据,以及使用什么方法进行验证:
‒ 若该列有三个唯一值,则:
最小值用于指定训练集。
中间值用于指定验证集。
最大值用于指定测试集。
‒ 若该列有两个唯一值,则仅使用训练集和验证集。
验证列 K 重
(仅当“Y,响应”列恰好有两个水平并且在启动窗口中指定了验证列时才可用。)使用指定验证列中的值将数据划分为 K 个集,其中 K 是列中唯一值的数目。然后,执行 K 重验证。
无
未使用验证。
执行
拟合指定的 SVM 模型并显示模型报表。
注意:若有大型数据表,则会为拟合数据的每个模型显示一个进度条。模型拟合的总数为 k!/2(k-2)!,其中 k 是响应变量的水平数。每个进度条都有一个接受当前估计值按钮。若您想要提前停止拟合算法并接受当前估计值,点击该按钮。由于预测计算是在点击该按钮后执行的,因此可能需要一些时间才能显示报表。