分类响应的报表
样本数据表 Diabetes.jmp 用于创建分类响应 Y 二值型的报表。
图 4.6 分类响应的分割报表
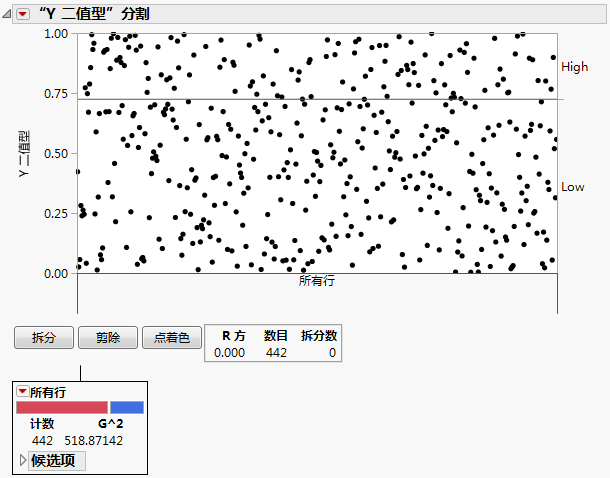
分割图
分割图中的每个点表示数据表中的一个观测。若使用了验证,该图仅用于训练数据。初始分割图不显示拆分。
请注意以下情况:
• 左侧的垂直轴是每个响应结果的比例。
• 右侧的垂直轴显示标绘响应水平的顺序。
• 水平线按响应变量划分每个拆分。初始水平线显示数据集中第一个标绘的响应的总体比例。
• 拆分显示在 X 轴下(它具有文本说明和在图中拆分观测的垂直线)。该垂直线延伸到图并指示每个节点的边界。最近的拆分直接显示在水平轴下,且在现有拆分之上。使用决策树的每个拆分或剪除更新该图。
汇总报表
图 4.7 分类响应的汇总报表

“汇总报表”提供训练数据、验证数据和测试数据(若使用)的拟合统计量。“汇总面板”中的拟合统计量随着您添加拆分或剪除决策树而更新。
R 方
R2 的当前值。
数目
观测数。
拆分数
决策树中的当前拆分数。
节点报表
树中的每个节点都有一个报表和一个包含附加选项的红色小三角菜单。末端节点也有“候选项”报表。
图 4.8 分类响应的末端节点报表
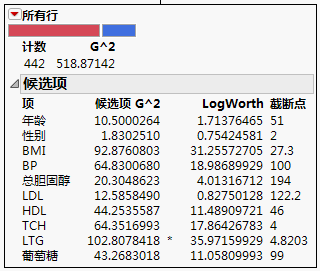
计数
由节点表征的训练观测数。
G2
用于分类响应的拟合统计量(而非用于连续响应的平方和)。较小的值指示更好的拟合。请参见“分割”平台的统计详细信息。
候选项
对于每列,“候选项”报表都提供有关该列的最优拆分的详细信息。用星号标记所有项上的最优拆分。
项
显示候选项列。
候选项 G^2
最佳拆分的似然比卡方。在具有最大 G^2 的预测变量上拆分将最大程度简化模型 G^2。
LogWorth
LogWorth 统计量,定义为 -log10(p 值)。最优拆分是使 LogWorth 得到最大值的拆分。请参见“分割”平台的统计详细信息。
截断点
确定拆分的预测变量的值。对于分类项,列出最左侧拆分中的水平。
最优拆分通过一个星号来标注。不过在某些情况下,“候选项 G2”最大值与“Logworth”最大值对应的不是同一个变量。在这种情况下,使用 > 和 < 为每个变量指出最佳方向。星号对应于两者一致的状况。请参见“分割”平台的统计详细信息。