发布日期: 04/13/2021
显示拟合详细信息
图 4.12 分类响应(Diabetes.jmp 中的 “Y 二值型”)的拟合详细信息
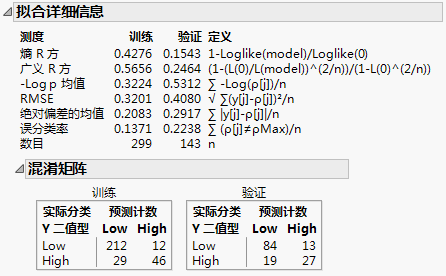
熵 R 方
比较拟合模型和恒定概率模型的对数似然的一种拟合测度。熵 R 方的范围介于 0 到 1 之间,其中接近 1 的值指示拟合更佳。请参见熵 R 方。
广义 R 方
可以应用到一般回归模型的测度。它基于似然函数 L,并且统一尺度后最大值为 1。对于标准最小二乘设置中的连续正态响应,“广义 R 方”测度简化为传统 R 方。“广义 R 方”亦称 Nagelkerke/Craig and Uhler R2,它是 Cox and Snell 伪 R2 的标准化版本。请参见 Nagelkerke (1991)。值越接近 1 指示拟合效果越好。
-Log p 均值
-log(p) 的平均值,其中 p 是与发生的事件有关的拟合概率。值越小指示拟合效果越好。
RMSE
均方根误差,其中差值为响应和 p(实际发生事件的拟合概率)之间的差值。值越小指示拟合效果越好。
绝对偏差的均值
响应和 p(实际发生事件的拟合概率)的差值绝对值的平均值。值越小指示拟合效果越好。
误分类率
具有最高拟合概率的响应类别不是观测到的类别的比率。值越小指示拟合效果越好。
“混淆矩阵”报表显示针对训练集以及验证集和测试集(若定义)的矩阵。混淆矩阵是实际响应和预测响应的双向分类。
若响应具有“收益矩阵”列属性,或者您使用“指定收益矩阵”选项指定了成本,则会显示“决策矩阵”报表。请参见“决策矩阵”报表。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).