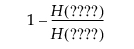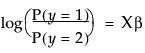

其中 F(x) 是标准 Logistic 分布的累积分布函数:
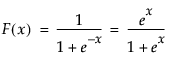
对于 r 个响应水平,JMP 拟合响应是数据值所给定的 r 个不同响应水平之一的概率。概率估计值必须均为正值。对于给定的 Xs 配置,响应水平上的概率估计值之和必须为 1。JMP 用于预测概率的函数是线性模型和多响应 Logistic 函数的组合。这有时称为对数线性模型,因为概率比的对数是线性模型。JMP 将每个响应概率与第 r 个概率关联并对这 r - 1 个模型分别拟合一组设计参数。
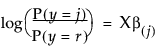 (对于
(对于 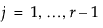 )
)该拟合原理称为最大似然。它估计参数以使数据给定的所有响应的联合概率为可从模型获得的最大概率。不直接报告联合概率(似然),报告似然的负对数合计更方便。
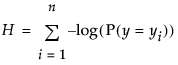
名义型模型的拟合会需要很长时间并且占用很多内存,有很多响应水平时更是如此。JMP 使用迭代历史记录跟踪计算进度,该记录显示负对数似然值在收敛到估计值的过程中逐渐变小。
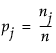
R2 统计量测量模型所解释的不确定性部分,公式为: