|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
为列获取“分布”报表时(通过选择分析 > 分布),JMP 会使用指定的分布自动估计拟合。表示拟合分布的曲线叠加在直方图上。
|
•
|
若定制的边界文件位于默认定制地图目录中,则只需在 -Name 文件中指定“地图角色”属性。
|
|
•
|
若定制的边界文件位于其他位置,则必须在 -Name 文件和所分析的数据表中指定“地图角色”属性。
|
|
1.
|
右击包含边界的列,然后选择列属性 > 地图角色。
|
|
2.
|
选择形状名称定义。
|
|
3.
|
点击确定。
|
|
4.
|
|
1.
|
右击包含边界的列,然后选择列属性 > 地图角色。
|
|
2.
|
选择形状名称使用。
|
|
3.
|
|
4.
|
在形状定义列旁边,输入地图数据表中值与选定列中的值匹配的列的名称。
|
|
5.
|
点击确定。
|
|
6.
|
|
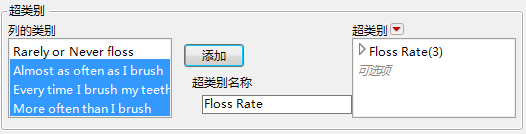
2.
|
选择列属性 > 超类别。
|
|
5.
|
点击添加创建超类别。
|
|
6.
|
从超类别红色小三角菜单中,在以下选项中进行选择:
|
|
‒
|
选项 > 隐藏:隐藏报表和图形中选定超类别的数据。
|
|
‒
|
全部添加:从列中的所有类别创建一个超类别。
|
|
‒
|
|
7.
|
点击确定将属性添加至列。
|
图 5.5 超类别配置示例
多重响应一词是指列中单元格包含不止一个响应值的情况。例如,Consumer Preferences.jmp 样本数据表的刷牙分隔列中的许多单元格都包含多个值。例如,第 6 行包含“Wake, After Meal, Before Sleep”。
图 5.6 “多重响应配置”窗口
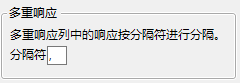
注意:您可以在“分类”平台中使用“多重响应”属性。详细信息,请参见《消费者研究》手册中的“多重响应”。您还可以在“数据过滤器”中使用该属性。请参见数据过滤器。若分隔符为逗号,请考虑改用“多重响应”建模类型。
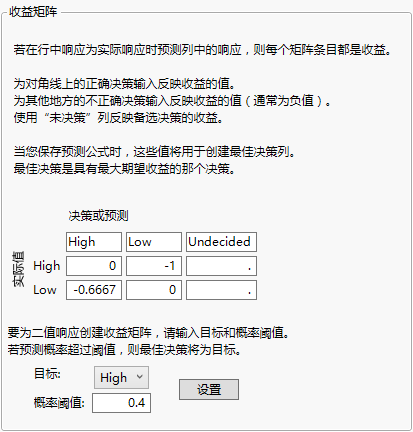
选择列属性 > 收益矩阵后会显示一个矩阵模板,选定列中的每个值都对应一行和一列。实际水平显示为行,预测水平显示为列。正确的决策是位于对角线上的决策,此处的预测水平等于实际水平。
用 t 表示阈值概率。点击“设置”时,收益矩阵中的条目按如下方式指定:
|
•
|
-t/(1 - t) 表示实际值为目标水平时所预测的非目标水平
|
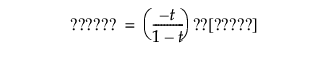
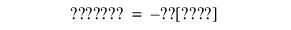
“最佳收益预测”是具有这两值中较大收益的水平。从上面这两个收益等式可以推断出:只要概率[目标水平] 至少为 t,观测即分配给目标水平。
|
•
|
<水平> 的收益:对于每个响应水平,会有一列给出用于将每个观测分类到该水平中的期望收益。
|
|
•
|
<列名> 的最佳收益预测:对于每个观测,给出具有最高期望收益的响应的水平。
|
|
•
|
<列名> 的期望收益:对于每个观测,给出“最佳收益预测”列定义的分类的期望收益。
|
|
•
|
<列名> 的实际收益:对于每个观测,给出用于将该观测分类到“最佳收益预测”列所指定的水平中的实际收益。
|
图 5.7 “收益矩阵”窗口的示例
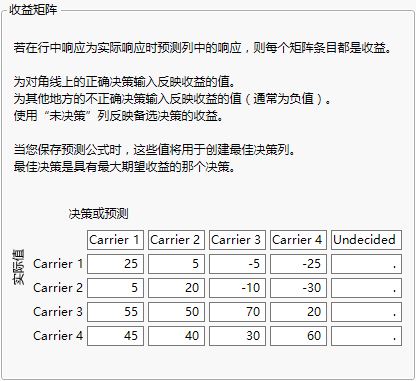
要查看如何在该收益矩阵中赋值,请考虑一个旅行社的情形:该旅行社通过四个航空公司(Carrier 1 到 Carrier 4)来为其客户提供服务。对于售出的每张机票,该旅行社都根据客户选择的航空公司来赚取利润。若旅行社推荐或预测了某家航空公司,它需为预订机票支付一小笔预订费。若客户决定乘坐预测的航空公司的航班,旅行社的收益中将扣除这笔预订费。但是,若客户决定乘坐另一家航空公司的航班,旅行社就会损失预订费,还必须支付另一笔预订费。旅行社的收益因为预测不准而降低。
样本数据表 Liver Cancer.jmp 包含 136 位患者的疾病严重性等级。您关注的是如何使用从 BMI 到黄疸这些列中给出的预测变量对“严重性”建模。通常的模型预测公式会将患者分类到最可能的严重性水平中。不过,与将实际上严重性“低”的患者归入严重性“高”的患者的错误相比,将实际上严重性“高”的患者归入严重性“低”的患者的错误为代价高的错误。因此,对于患者病情严重性实际很高的情况,您想要为将这些患者误分类为“低”的情况分配更高的成本。
|
1.
|
|
2.
|
选择“严重性”列并选择列 > 列信息。
|
|
3.
|
|
4.
|
将“目标”改为 High。
|
|
5.
|
输入 0.4 作为概率阈值。
|
|
6.
|
点击设置。
|
图 5.8 显示与概率阈值对应的权重的收益矩阵