基于所选的拟合方法,“拟合最小二乘法”报表提供不同的分析结果并提供“保存列”和“刻画器”的更多菜单选项。尤其需要指出,“方差分析”报表并不显示,因为方差和自由度未按照通常方式分割。您可以从“REML 方差分量估计值”报表获取残差方差估计值。(请参见REML 方差分量估计值。)对于检验固定效应的情况,“效应检验”报表被“固定效应检验”报表取代。其他报表提供随机效应的预测值以及关于方差分量的详细信息。
REML 方法的“拟合最小二乘法”报表显示了使用 REML 方法拟合 Investment Castings.jmp 样本数据所获取的报表。运行脚本模型 - REML,然后拟合该模型。请注意,铸件是嵌套在温度内的随机效应。
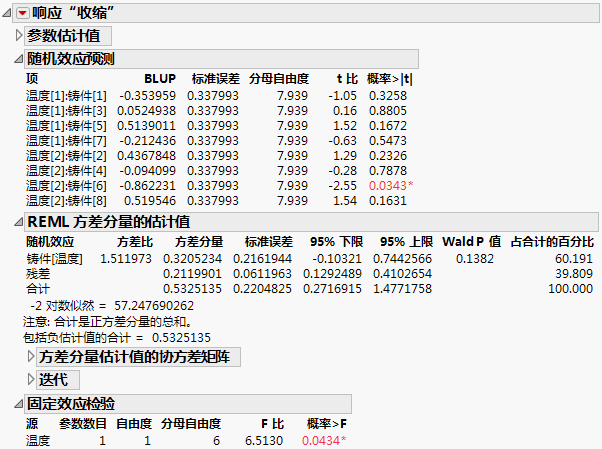
对于模型中的每个项,该报表提供其最佳线性无偏预测变量 (BLUP) 的经验估计值,以及针对相应系数是否为 0 的检验。
提供针对效应为 0 的检验的分母自由度。多数情况下,t 检验的自由度是小数。
提供检验的 p 值。
最佳线性无偏预测变量 (BLUP) 一词指的是随机效应的估计量。具体而言,它是所有无偏估计量中可最小化均方预测误差的估计量。“随机效应预测”报表提供 BLUP 的估计值或经验 BLUP。这些之所以是经验值是因为 BLUP 依赖方差分量的值,而这些值是未知的。方差分量的估计值被代入 BLUP 的公式中,生成了报表中所示的估计值。
在 REML 方法中,使用方差分量估计值来估计固定效应的标准误差。不过,若不考虑这些估计值中的变异性,则会低估标准误差。要考虑增大的变异性,可以使用 Kackar-Harville 校正 (Kackar and Harville, 1984 以及 Kenward and Roger, 1997)来调整固定效应的协方差矩阵。涉及固定效应的协方差矩阵的所有计算都使用该校正。这些计算包括最小二乘均值、固定效应检验、置信区间和预测方差。有关统计详细信息,请参见Kackar-Harville 校正。
通过将仅依赖于这些参数的残差对数似然函数最大化,可获得 σ2 的估计值和 G 中的方差分量。迭代过程尝试将残差对数似然函数最大化,或等效于将负残差对数似然的两倍(–2对数似然)最小化。“迭代”报表提供有关该过程的详细信息。
收敛准则基于梯度,默认容差为 10-8。您可以在“拟合模型”启动窗口中更改该准则,只需选择“收敛设置”>“收敛极限”选项并指定所需容差即可。
提供计算的 F 比。
提供效应检验的 p 值。
使用 REML 方法时,“保存列”菜单中将额外显示六个选项。这些选项的名称以条件一词开头。该前缀指示这些列的计算使用随机效应关联项的预测值,而不是其期望值 0。