Risk-Based Monitoring Supplemental Data Table
The supplemental data set is used to enter any data (external to the database or otherwise) used by the RBM system. It is modeled after a CDISC event domain, and uses the two-letter prefix RB.
Variables in Supplemental Data Sets
Required Variables: The supplemental RB data set must contain the variables listed in the following table:
|
Variable Names |
Variable Labels |
Type |
Notes |
Required |
|
STUDYID |
Study Identifier |
Character |
Study ID. Likely not used directly in the code. |
|
|
USUBJID |
Unique Subject Identifier |
Character |
Used to match subject-level summary data derived from this data set to the CDISC data used in JMPC (minimum DM and DS) for analysis. |
Yes but it needs to be populated only for subject-level data. If site-level data is entered, USUBJID needs to be left blank. |
|
SITEID |
Study Site Identifier |
Character |
To provide site-level data for analysis. In these cases, USUBJID would be missing. |
Yes |
|
VARIABLE |
Variable |
Character |
Short code that is used as variable name within SAS code, for example, "QUERY". Special codes: QUERY, CRFPAGE. |
Yes |
|
RBDECOD |
Standardized Term |
Character |
Standardized term for analysis. This is used as label for variable specified within VARIABLE, "Query", for example. Within the same analysis, subject and site-level variables cannot share the same values for VARIABLE and RBDECOD. In other words, variable names and labels must be distinct. Subjects without an instance of a particular VARIABLE and RBDECOD are assumed of have 0 instances |
Yes |
|
RBTERM |
Reported Term |
Character |
Term that can provide more specific detail. Not used directly by system, for example, “inconsistency with gender and pregnancy findings”. |
|
|
RBCAT |
Category |
Character |
One of Enrollment, Disposition, Safety or Supplemental. This determines the group of variables the variable resides with in the analysis table, and has implications on which subcategory overall indicator it contributes toward. May allow for more general categories in a future version |
Yes |
|
RBSTDTC |
Start Date/Time |
Character, ISO 8601 |
Start date of event. This determines where events are presented for time trends. |
Yes |
|
RBENDTC |
End Date/Time |
Character, ISO 8601 |
End date of event. This is to determine responsiveness to completing tasks (such as queries), or if missing, if an item is considered OVERDUE |
If missing, RBENDTC assumed to equal RBSTDTC. |
|
RBFREQ |
Frequency |
Numeric |
The frequency the current record should be weighted for analysis. |
If not used or value missing, the row is assumed to occur a single instance. |
Site Level Variables: Risk-Based Monitoring (RBM) supports site-level variables in the supplemental data set. These are identified by having USUBJID missing. Study Site Identifier (SITEID) is a required variable for this format. Because dates can be provided, site-level variables should be summarized in time trend analyses. Within the same analysis, subject and site-level variables cannot share the same values for VARIABLE and RBDECOD.
Example 1: Protocol deviations computed by the biostatistics team
|
USUBJID |
Variable |
RBDECOD |
RBTERM |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
10101 |
PROTDEV |
Protocol Deviation |
Long Text |
Disposition |
2004-12-1 |
2004-12-1 |
1 |
|
10101 |
PROTDEV |
Protocol Deviation |
Long Text |
Disposition |
2004-12-4 |
2004-12-4 |
1 |
|
10104 |
PROTDEV |
Protocol Deviation |
Long Text |
Disposition |
2004-12-4 |
2004-12-4 |
2 |
Subject 10104 had 2 protocol deviations on December 4th. In site level table, PROTDEV is the sum of all protocol deviations for a site. PROTDEV is the country-level sum of deviations for each country. If subjects, sites or countries are not represented, they have a value of 0. RBMTERM can be used to distinguish between specific events. To count different types of deviations, this would require multiple sets of codes. For example, if you want a count of all and clinically-relevant deviations, the clinically-relevant deviations would need additional rows in the table with a new code and label (for example, CPROTDEV). These frequency variables have additional variables created for total averaged by # randomized subjects (AVPROTDEV) and by # patientweeks (PWPROTDEV).
Computed Eligibility Violations would work in the same way (if a SAS program calculated these, for example). Alternatively, specific hospitalization of interest (that would ultimately end up in the HO domain) could be collected in this manner.
Example 2: QUERY
|
USUBJID |
Variable |
RBDECOD |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
10101 |
QUERY |
QUERY |
Supplemental |
2004-12-1 |
2004-12-1 |
1 |
|
10101 |
QUERY |
QUERY |
Supplemental |
2004-12-4 |
|
1 |
|
10104 |
QUERY |
QUERY |
Supplemental |
2004-12-4 |
2004-12-4 |
2 |
Subject 10104 had 2 queries on December 4th that were resolved the same day. In site level table, QUERY is the sum of all queries for a site. QUERY is country-level sum of queries for each country. If subjects, sites or countries are not represented, they have a value of 0. Frequency variables have additional variables created for total averaged by # randomized subjects (AVQUERY) and by # patientweeks (PWQUERY). The special term QUERY also calculates OQUERY as the count of queries with missing RBENDTC. The word "Overdue" is added to QUERY label listed in RBDECOD (here, resulting in RBEDCOD value of Overdue Query). Similar averages are computed for # randomized subjects and patient weeks. The special term QUERY also calculates RQUERY, which is the average query response time (# days between RBSTDTC and RBENDTC) for all queries for a subject, site, or country, taking into consideration RBFREQ.
Example 3: CRFPAGE
It would be possible to include records for each CRF page a subject is expected to enter. Alternatively, the total completed pages or incomplete pages could be tracked. Here, RBSTDTC represents the date on which the visit occurred, while RBENDTC represents the date on which the page (paper or electronic) was completed.
|
USUBJID |
SITEID |
Variable |
RBDECOD |
RBTERM |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
10101 |
10 |
CRFPAGE |
CRF Page |
Page 1 |
Supplemental |
2004-12-1 |
2004-12-1 |
1 |
|
10101 |
10 |
CRFPAGE |
CRF Page |
Page 2 |
Supplemental |
2004-12-4 |
|
1 |
|
10104 |
10 |
CRFPAGE |
CRF Page |
Page 1 |
Supplemental |
2004-12-4 |
2004-12-4 |
2 |
In site level table, CRFPAGE is the sum of all pages for a site. CRFPAGE is the country-level sum of pages for each country. If subjects, sites or countries are not represented, they have a value of 0. Frequency variables have additional variables created for total averaged by # randomized subjects (AVCRFPAGE) and by # patientweeks (PW CRFPAGE). The special term CRFPAGE also calculates OCRFPAGE as the count of incomplete CRF Pages with missing RBENDTC. The word "Overdue" added to CRFPAGE label listed in RBDECOD (here, resulting in RBEDCOD value of Overdue CRF Pages). Similar averages are computed for # randomized subjects and patient weeks. The special term CRFPAGE also calculates RCRFPAGE, which is the average CRF entry time (# days between RBSTDTC and RBENDTC) for all CRF pages for a subject, site, or country, taking into consideration RBFREQ. Above is one row per page. Alternatively,
|
USUBJID |
SITEID |
Variable |
RBDECOD |
RBTERM |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
10101 |
10 |
CRFPAGE |
CRF Page |
Visit 1 |
Supplemental |
2004-12-1 |
2004-12-3 |
20 |
|
10101 |
10 |
CRFPAGE |
CRF Page |
Visit 2 |
Supplemental |
2004-12-1 |
|
5 |
Here, subject 10101 had 20 pages completed for Visit 1 (Visit 1 occurred December 1, but these pages were entered on December 3), though 5 are missing. Duration would be computed as 3 days for the 20 pages. If only below is provided, the CRFPAGE and OCRFPAGE results should be similar, though RCRFPAGE is not be computed.
|
USUBJID |
SITEID |
Variable |
RBDECOD |
RBTERM |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
10101 |
10 |
CRFPAGE |
CRF Page |
Visit 2 |
Supplemental |
2004-12-1 |
|
5 |
Example 4: SITEDEV
A site-level deviation variable could be added to distinguish between protocol deviations perpetrated by the site and by the subject (PROTDEV above). Here, USUBJID is blank to tell JMP Clinical that this is a site-level variable.
|
USUBJID |
SITEID |
Variable |
RBDECOD |
RBTERM |
RBCAT |
RBSTDTC |
RBENDTC |
RBFREQ |
|
|
10 |
SITEDEV |
Site Deviation |
|
Supplemental |
2004-12-1 |
2004-12-1 |
1 |
|
|
10 |
SITEDEV |
Site Deviation |
|
Supplemental |
2004-12-4 |
2004-12-4 |
1 |
|
|
10 |
SITEDEV |
Site Deviation |
|
Supplemental |
2004-12-4 |
2004-12-4 |
1 |
How Supplemental Data Tables are Used by JMP Clinical.
Prior to version 6.0, analyses using the Risk Based Monitoring (RBM) report were based entirely on one or more domains of the study database and data supplied at the site level. Data was entered manually using Update Study Risk Data Set. However, this protocol is inadequate for the study team that wishes to assess data quality for data captured outside of the study database, for endpoints that are captured at either the patient or site level, with considerations for when the data was captured. This includes data from database management systems (queries, CRF entry), randomization systems, protocol deviations or eligibility violations identified through statistical programming, or any deviations identified by clinical monitors while on site. RBM analyses can accommodate a supplemental data set. This enhancement enables clinical trial sponsors to specify a data set of additional endpoints that can be included in the RBM report.
The supplemental data set is not considered part of the study folders that can be updated periodically in the form of snapshots, largely because of the variable timing these other data might become available. However, the supplemental data can include complex calculations of the current, more-recent or any past study database for inclusion into the RBM analysis. For example, through the RBM dialog users can subset to particular adverse events or health care encounters of interest for analysis. For example, if users were interested solely in adverse events that occurred during health care encounters, the statistical team can develop programming to identify these adverse event records and supply them using the supplemental data set for analysis.
Specifying a Supplemental Data Set
A supplemental data can be specified through the Risk-Based Monitoring report(circled below).
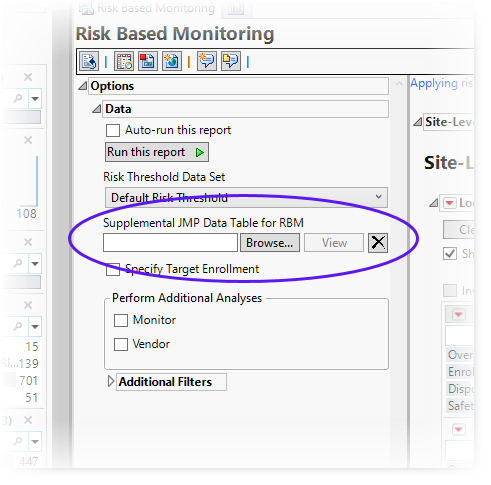
By default, JMP Clinical looks first in the RBMSupplemental subfolder found in the user folder (typically located in the C:\Users\username\OneDrive - SAS\Documents\JMPClinical18\Configurations\Default\RBMSupplemental\rb_en.jmp directory), although supplemental data sets can be stored anywhere.

The Nicardipine sample data included with JMP Clinical, has an example supplemental data set (rb_en.jmp, English version).
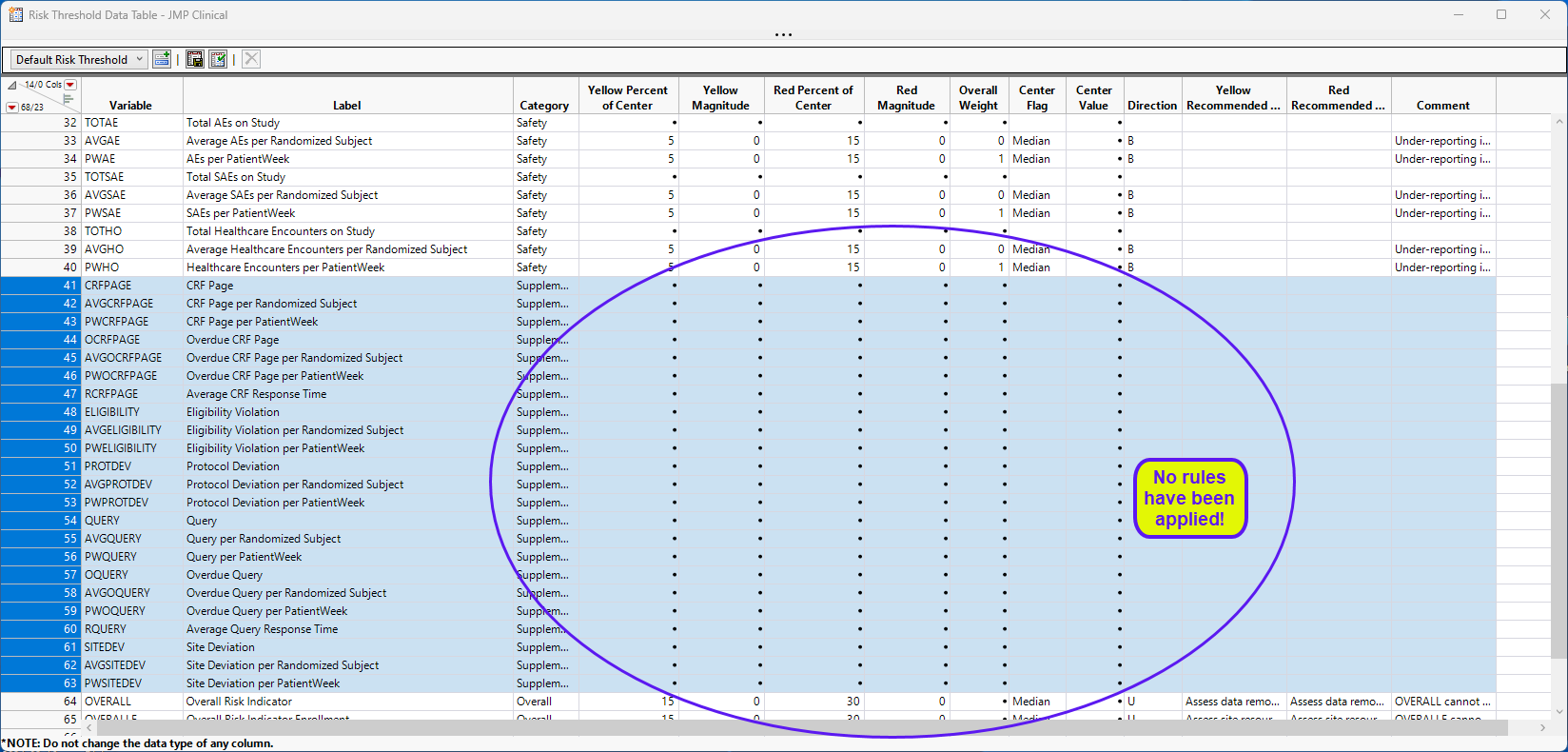
This risk threshold data set includes rows for the variables included in the supplemental data set, as well as:
| • | Risk indicators normalized by the number of patients |
| • | Risk indicators normalized by the number of patient weeks |
| • | Additional indicators for the number of incomplete CRF pages and queries, as well as average times for completion based on the usage of special variable codes as documented in the supplemental standard above. |
Running this analysis will include these variables in the output and consider the variables for any overall indicators that they happen to be a part of.
Updating the Risk Threshold Data Table With Supplemental Variables
To add supplemental indicators, you first need to manage the risk threshold data table (which enables you to delete, update, or add new variables to a base risk threshold data set). The Risk Threshold data table is accessed from a link on the Settings tab of the JMP Clinical Main (below).
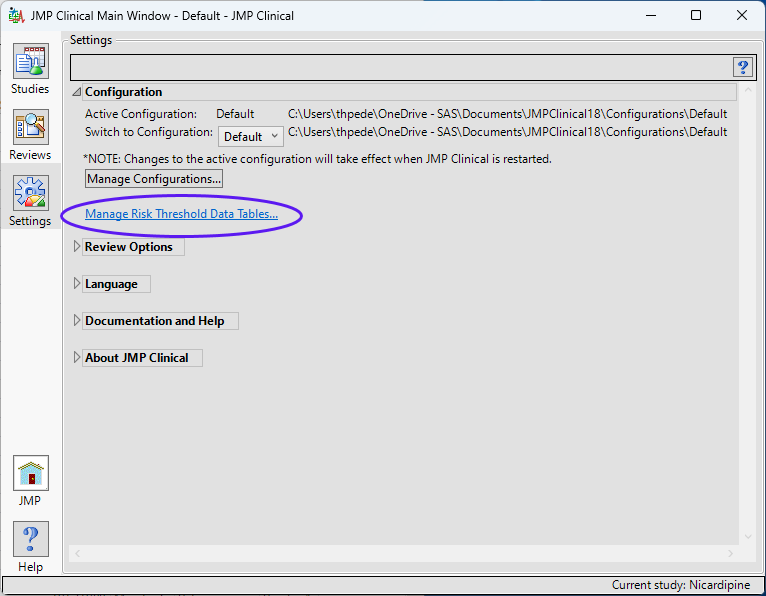
Clicking Manage Risk Threshold Data Tables... opens the default risk threshold data set (shown below).
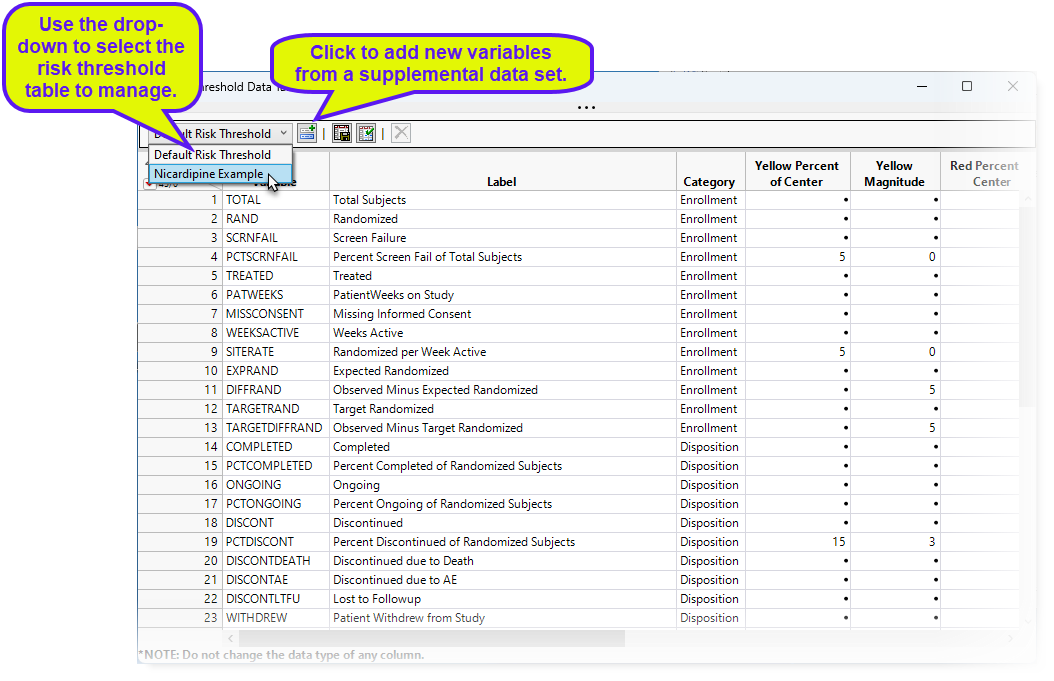
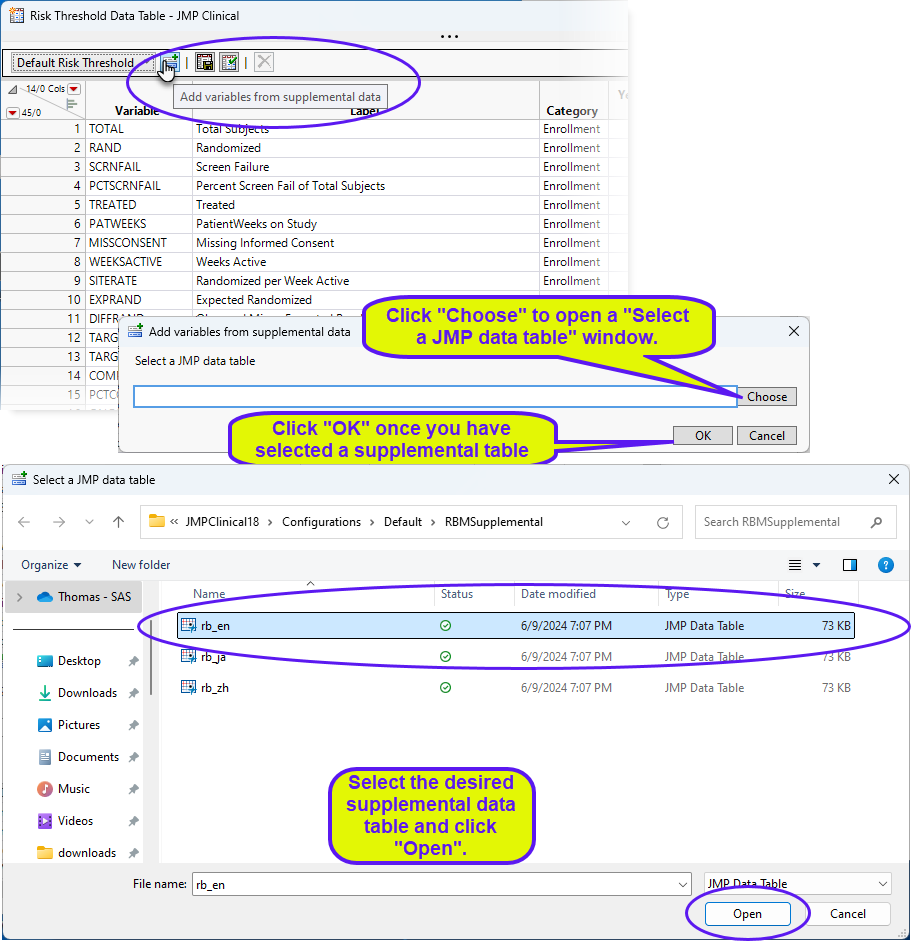
To add new variables from a supplemental data set, click  . An Add variables from supplemental data opens. Click to open a Select a JMP data table showing the contents of the supplemental data set folder. Select the desired supplemental data set and click . Return to the Add variables from supplemental data and click .
. An Add variables from supplemental data opens. Click to open a Select a JMP data table showing the contents of the supplemental data set folder. Select the desired supplemental data set and click . Return to the Add variables from supplemental data and click .
This report adds a number of additional variables (Supplemental, because this is the defined Category in the rb_en.sas7bdat data set). This data set can now have rules applied to the variables and can be saved with a new name to be used by theRisk Based Monitoring report. Note that the only difference between the data set shown below and the Nicardipine Example risk threshold data set is that there are no rules defined in the data set shown below. The data set as defined below enables an analysis of the supplemental data, but without any coloring of the risk indicators according to any rules.