Running this process for the Nanostring_20090806 sample setting generates the Results window shown below. Refer to the Nanostring Input Engine process description for more information.
The Results window contains the following elements:
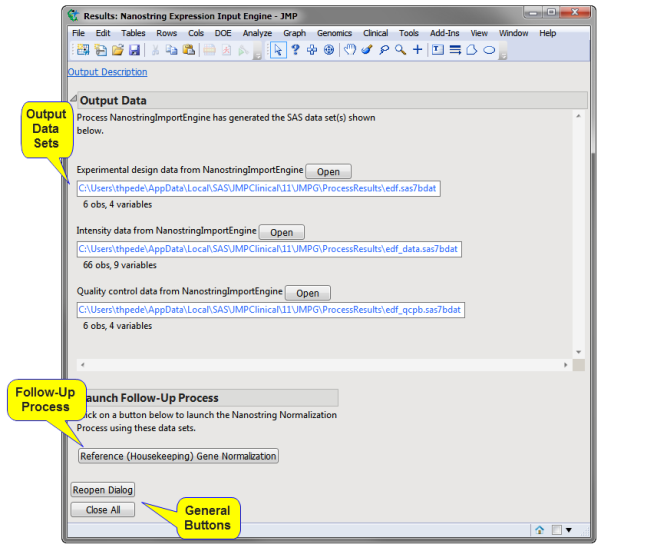
Output Data
This process generates the following data set:
•
Experimental Design Data Set (EDDS): This data set lists specific information about experimental details for each of the arrays. Refer to Experimental Design Data Set (EDDS) for more information about this data set.
•
Output Data Set: This data set contains the intensity data from the inputfile.
•
Quality Control Data Set: This data set is generated only when one or more of the QC options on the QC tab of the process dialog are checked. This data set lists the ColumnName of the flagged sample, and the values for the Imaging QC, Binding Density QC, and/or Positive Control Linearity QC.
•
Output Wide Data Set: This data set contains the intensity data from the inputfile in wide format.
•
Annotation Data Set: This data set contains all of the annotation information (gene names, accession numbers, and codeset information.) from the input files.
Note: You can view the data in a file or data set by clicking either or (when the data set is very large).
Launch Follow-up Processes
•
Reference (Housekeeping) Gene Normalization: Click to launch the Reference Gene Normalization process with the output data set specified as input.
General
•
Click to reopen the completed process dialog used to generate this output.
•
Click to close all graphics windows and underlying data sets associated with the output.