Process Description
Flip Strand
The Flip Strand process compares the major and minor allele for SNPs in an Annotation Data Set to a reference annotation data set and flips the strand (in other words switches both alleles to their complements) for non-A/T and non-C/G SNPs that have the complementary alleles in the reference set. A/T and C/G SNPs can be flipped as well.
What do I need?
Two Annotation Data Sets are required to run this process. An annotation data set contains information, such as gene identity or chromosomal location, for each of the markers. Annotation data sets are tall data sets; each row corresponds to a different marker. The two data sets must describe the same markers.
The annotation data set used in this example, the samplemap_orig.sas7bdat data set, was computer generated and identifies markers, location and gene identities. A portion of this data set is illustrated below.
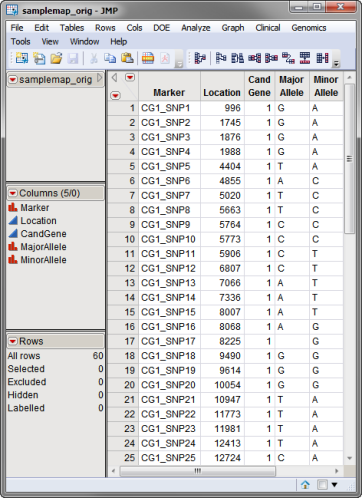
A second reference Annotation Data Set is also required. This data set is generated from a separate experiment (from a reference population, for example, or from the same population but using a different machine or protocol) and serves as a standard for evaluating the first experiment. The reference annotation data set used in this example, the samplemap_ref.sas7bdat data set, was computer generated and identifies markers, location and gene identities. A portion of this data set is illustrated below.
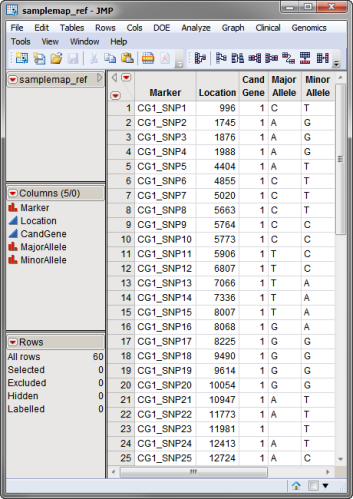
| 8 | Compare the two data sets above and note some of the differences. |
For detailed information about the files and data sets used or created by JMP Genomics software, see Files and Data Sets.
Output/Results
The output generated by this process is summarized in a Tabbed report. Refer to the Flip Strand output documentation for detailed descriptions and guides to interpreting your results.