|
1.
|
[ヘルプ]>[サンプルデータライブラリ]を選択し、「Pizza Responses.jmp」を開きます。
|
|
2.
|
「選択モデル」スクリプトの緑色の三角ボタンをクリックします。
|
|
3.
|
「選択モデル」の赤い三角ボタンをクリックし、[被験者ごとの勾配を保存]を選択します。
|


|
4.
|
「階層型クラスター分析」スクリプトの緑色の三角ボタンをクリックします。
|
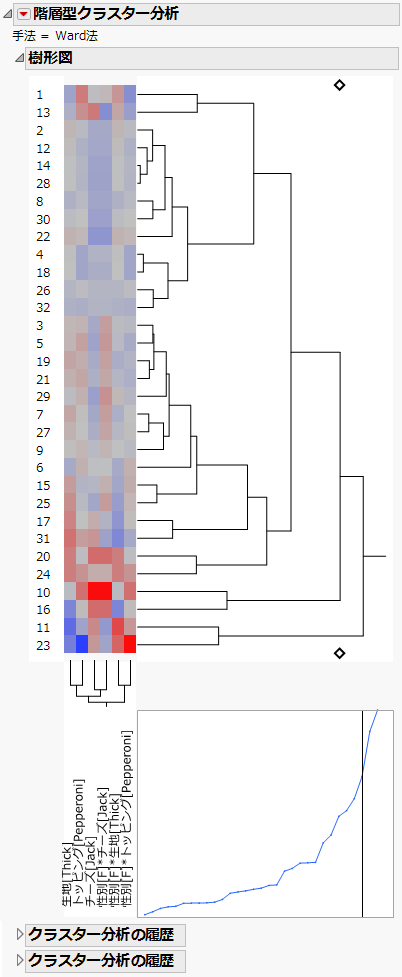
このスクリプトは、勾配のテーブルにある「被験者」列を除くすべての列を対象に、階層型クラスター分析を行います。いずれかのひし形をクリックすると、行が3つのクラスターに分かれていることがわかります。
|
5.
|
「階層型クラスター分析」の赤い三角ボタンをクリックし、[クラスターの保存]を選択します。
|
勾配を保存したデータテーブルに「クラスター」という列が追加されます。同じぐらいの勾配を持つ被験者が、同じクラスターに分けられます。階層型クラスター分析のその他のオプションについては、『多変量分析』の「階層型クラスター分析」章を参照してください。
|
6.
|
|
7.
|
「元データに結果をマージ」スクリプトの横にある緑色の三角ボタンをクリックします(ピザのデータから計算された被験者ごとの勾配(一部))。
|
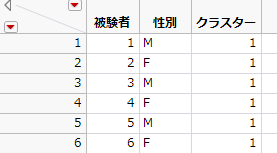
クラスター情報が「被験者」データテーブルにマージされます。これで、「被験者」データテーブルの列は「被験者」、「性別」、「クラスター」の3つになりました(「被験者」データテーブルに加わった「クラスター」列)。
|
1.
|
|
2.
|
[分析]>[二変量の関係]を選択します。
|
|
3.
|
「性別」を選択し、[Y, 目的変数]をクリックします。
|
|
4.
|
「クラスター」を選択し、[X, 説明変数]をクリックします。
|
|
5.
|
[OK]をクリックします。
|

場合によっては、「クラスター」変数を含めた選択モデルをあてはめてみてもよいでしょう。