信息性缺失的示例
在该示例中,您构建一个决策树模型来预测客户是否有信用风险。因为您的数据集包含缺失值,您也探索了“信息性缺失”选项的效用。
启动“分割”平台
1. 选择帮助 > 样本数据库,然后打开 Equity.jmp。
2. 选择分析 > 预测建模 > 分割。
3. 选择不良并点击 Y,响应。
4. 从贷款一直选到负债收入比,然后点击 X,因子。
5. 点击确定。
使用“信息性缺失”创建决策树和 ROC 曲线
1. 按住 Shift 键并点击拆分。
2. 为拆分数输入 5,然后点击确定。
3. 点击“‘不良’分割”旁边的红色小三角菜单,然后选择 ROC 曲线。
4. 点击“‘不良’分割”旁边的红色小三角菜单,然后选择保存列 > 保存预测公式。
列 Prob(不良==良性风险) 和 Prob(不良==不良风险) 包含“信息性缺失”实用工具用来将未来贷款申请者的信用风险分类的公式。您想比较该模型与不使用“信息性缺失”的模型的分类效果。
不使用“信息性缺失”创建决策树和 ROC 曲线
1. 点击“‘不良’分割”旁边的红色小三角菜单,然后选择重新运行 > 重新启动分析。
2. 取消选择信息性缺失。
3. 点击“确定”并重复使用“信息性缺失”创建决策树和 ROC 曲线中的步骤。
列 Prob(不良==良性风险) 2 和 Prob(不良==不良风险) 2 包含不使用“信息性缺失”实用工具的公式。
比较 ROC 曲线
直观比较两个模型的 ROC 曲线。左侧的模型具有“信息性缺失”,右侧的模型没有“信息性缺失”。
图 4.23 具有(左)和没有(右)“信息性缺失”的模型的 ROC 曲线
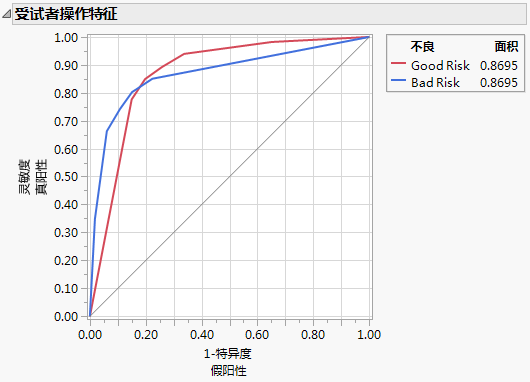
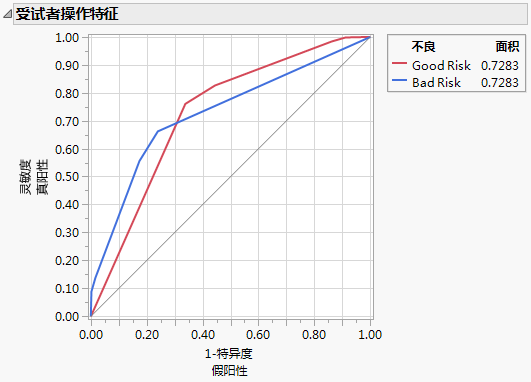
具有“信息性缺失”的模型的曲线下面积 (AUC) (0.8695) 大于没有“信息性缺失”的模型的 AUC (0.7283)。因为响应只有两个水平,每个模型的 ROC 曲线是另一个模型曲线的反射,且 AUC 相等。
注意:您的 AUC 可能不同于此处所示没有“信息性缺失”的模型的 AUC。不使用“信息性缺失”时,随机将缺失行分配到拆分两侧。重新运行分析可能导致结果略有不同。
使用“模型比较”平台
接着,使用“模型比较”平台比较模型,以比较您在step 4和step 3中创建的两组公式。
1. 选择分析 > 预测建模 > 模型比较。
2. 选择 Prob(不良==良性风险)、Prob(不良==不良风险)、Prob(不良==良性风险) 2 和 Prob(不良==不良风险) 2,然后点击 Y,预测变量。
第一对公式列包含具有“信息性缺失”的模型的公式。第二对公式列包含没有“信息性缺失”的模型的公式。
3. 点击确定。
图 4.24 模型比较的拟合测度

“拟合测度”报表显示第一个模型(使用“信息性缺失”拟合)的表现好于第二个模型(未使用“信息性缺失”拟合)。第一个模型具有更高的 R 方值以及更低的 RMSE 值和误分类率。这些结果与 ROC 曲线比较的结果相符。
注意:同样,由于未使用“信息性缺失”时的随机差异,您的结果可能不同。