发布日期: 04/13/2021
 朴素 Bayes 的示例
朴素 Bayes 的示例
您有 442 名糖尿病患者的基准医疗数据,还有在每名患者首次就诊一年后得到的糖尿病疾病发展的二值型测度。该测度将疾病发展量化为“Low”或“High”。您想构造一个分类模型以便在预测未来患者的疾病发展为“High”或“Low”时使用。
1. 选择帮助 > 样本数据库,然后打开 Diabetes.jmp。
2. 选择分析 > 预测建模 > 朴素 Bayes。
3. 选择 Y 二值型并点击 Y,响应。
4. 从年龄一直选到葡萄糖,然后点击 X,因子。
5. 选择验证并点击验证。
6. 点击确定。
图 8.2 “朴素 Bayes”报表
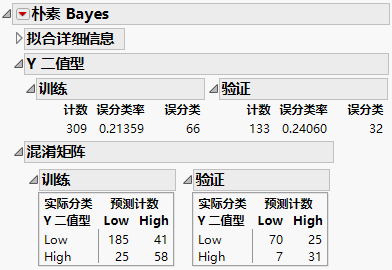
训练集大约有 21% 的误分类率,验证集大约有 24% 的误分类率。混淆矩阵指示对于训练集和验证集,较大的误分类源来自将具有“Low”疾病发展的患者归入具有“High”疾病发展一类。验证集结果指示模型如何扩展到独立观测。
您想了解哪些预测变量对朴素 Bayes 分类的影响最大。
7. 点击“朴素 Bayes”红色小三角并选择刻画器。
图 8.3 疾病发展的预测刻画器

8. 点击“预测刻画器”红色小三角并选择评估变量重要性 > 独立均匀输入。
图 8.4 变量重要性

“汇总报表”指示 HDL、BMI 和 LTG 对估计的概率具有最大影响。
图 8.5 “边缘模型图”报表

“边缘模型图”报表中图的第二行显示较高的 HDL 值与将患者归类为“High”的较小概率关联。而且,较高的 BMI 和 LTG 值与将患者归类为“High”的较大概率关联。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).