 启动“Bootstrap 森林法”平台
启动“Bootstrap 森林法”平台
通过选择分析 > 预测建模 > Bootstrap 森林法启动“Bootstrap 森林法”平台。
 启动窗口
启动窗口
图 5.7 “Bootstrap 森林法”启动窗口

有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
“Bootstrap 森林法”平台启动窗口提供以下选项:
Y,响应
您想要分析的一个或多个响应变量。
X,因子
预测变量。
权重
一列,该列的数值为分析中的每一行都分配一个权重。
频数
一列,该列的数值为分析中的每一行都分配一个频数。
验证
最多包含三个非重复值的数值列。请参见验证。
依据
一个或多个列,其水平定义不同的分析。对于指定列的每个水平,都使用您已经指定的其他变量分析相应行。结果显示在单独的报表中。若指定了多个“依据”变量,将为“依据”变量水平的每种可能组合生成单独的报表。
方法
支持您选择分割方法(决策树、Bootstrap 森林法、提升树、K 最近邻或朴素 Bayes)。这些备选方法(决策树除外)均在 JMP Pro 中提供。
有关这些方法的详细信息,请参见分割模型、提升树、K 最近邻和朴素 Bayes。
验证部分
要用作验证集的数据部分。请参见验证。
信息性缺失
若选定,则对于分类预测变量,将其缺失值单独作为一类;对于连续预测变量,则对其缺失值采取信息性处理。请参见信息性缺失。
有序型限制顺序
若选定,对于有序变量,在拆分时则会进行限定以维持有序变量水平的排序。
 规格窗口
规格窗口
在启动窗口中选择确定后,“Bootstrap 森林法规格”窗口随即显示。
图 5.8 “Bootstrap 森林法规格”窗口
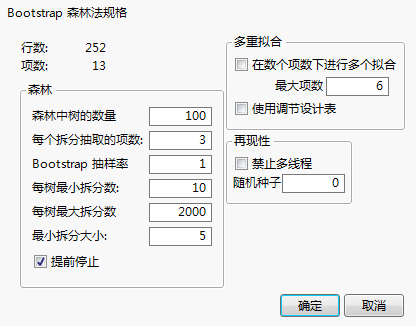
 规格面板
规格面板
行数
数据表中的行数。
项数
指定为预测变量的列数。
 “森林”面板
“森林”面板
森林中树的数量
要增长及随后求平均值的树个数。
每个拆分抽取的项数
要在每个拆分中视为拆分候选项的预测变量数。对于每个拆分,都会选新的随机预测变量样本作为候选集。
Bootstrap 抽样率
要为增长每棵树而抽取的观测比例(有放回)。会为每棵树生成新的随机样本。
每树最小拆分数
每棵树的最小拆分数目。
每树最大拆分数
每棵树的最大拆分数目。
最小拆分大小
候选拆分所需的最小观测数。
提前停止
(仅在使用验证时才可用。)在选定时,若更多树不会改善验证统计量,则过程会停止增长更多树。验证统计量是该验证集的熵 R 方(对于分类响应)或该验证集的 R 方值(对于连续响应)。若未选定,过程会继续,直到达到指定数量的树。
 “多重拟合”面板
“多重拟合”面板
在数个项数下进行多个拟合
若选定,则可以对“每个拆分抽取的项数”的多个可能的不同取值创建 Bootstrap 森林法。显示结果的模型就是验证集的熵 R 方值(对于分类响应)或 R 方(对于连续响应)最大的模型。
下限是“每个拆分抽取的项数”规格。上限由下面的选项指定:
最大项数
要考虑进行拆分的最大项数。
使用调节表设计
打开一个窗口,您可以在其中选择包含“森林”面板调节参数值的数据表(称为调节设计表)。调节设计表针对您想要指定的每个选项都有一列,并且包含一行或多行,每行都表示一个 Bootstrap 森林法模型设计。若未在调节设计表中指定任何选项,则使用默认值。
对于表中的每行,JMP 都使用指定的调节参数创建一个 Bootstrap 森林法模型。若在调节设计表中指定了不止一个模型,则“模型验证集汇总”报表列出每个模型的 R 方值。“Bootstrap 森林法”报表显示具有最大 R 方值的模型的拟合统计量。
您可以使用“实验设计”工具创建调节设计表。Bootstrap 森林法调节设计表可以包含以任意顺序排列的不区分大小写的以下列:
‒ 树的数量
‒ 项数
‒ 部分 Bootstrap
‒ 每树最小拆分数
‒ 每树最大拆分数
‒ 最小拆分大小
 “再现性”面板
“再现性”面板
禁止多线程
若选定,则在单个线程上执行所有计算。
随机种子
指定非零数值随机种子,以便将来启动该平台时重现结果。默认情况下,“随机种子”设置为零,即不生成可重现的结果。将分析保存到脚本中时,您输入的随机种子将保存到脚本中。