发布日期: 04/13/2021
启动“分割”平台
通过选择分析 > 预测建模 > 分割来启动“分割”平台。
图 4.5 “分割”启动窗口
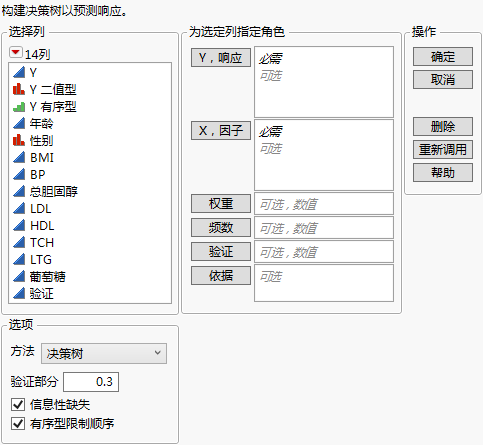
有关“选择列”红色小三角菜单中选项的详细信息,请参见《使用 JMP》中的“列过滤器”菜单。
Y,响应
您想要分析的一个或多个响应变量。
X,因子
预测变量。
权重
一列,该列的数值为分析中的每一行都分配一个权重。
频数
一列,该列的数值为分析中的每一行都分配一个频数。
 验证
验证
最多包含三个非重复值的数值列。请参见验证。
依据
一个或多个列,其水平定义不同的分析。对于列的每个水平,都使用您指定的其他变量分析相应行。结果显示在单独报表中。若指定了多个“依据”变量,将为“依据”变量水平的每种可能组合生成单独的报表。
 方法
方法
支持您选择分割方法(Bootstrap 森林法、提升树、K 最近邻或朴素 Bayes)。
有关这些方法的详细信息,请参见Bootstrap 森林法、提升树、K 最近邻和朴素 Bayes。
验证部分
要用作验证集的数据部分。请参见验证。
信息性缺失
若选定,则对于分类预测变量,将其缺失值单独作为一类;对于连续预测变量,则对其缺失值采取信息性处理。请参见信息性缺失。
有序型限制顺序
若选定,对于有序变量,在拆分时则会进行限定以维持有序变量水平的排序。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).