发布日期: 04/13/2021
边侧似然置信限
参数的置信上限和置信下限基于每个参数对于其他参数来说达到最小化之后,对该参数的值进行的一次搜索。该搜索查找符合以下条件的值:这些值所生成的误差平方和比解的最小误差平方和高出一定差值。这个差值的目标基于 F 分布。置信区间有时称为似然置信区间或边侧似然置信区间(Bates and Watts 1988;Ratkowsky 1990)。
边侧置信限都以目标误差平方和开始。这是 F 检验认为在给定的 alpha 水平下与解误差平方和存在显著差异的误差平方和(或损失函数之和)。若将损失函数指定为负对数似然,则使用卡方分位数替代 F 分位数。针对每个参数的置信上限,增加参数值直到误差平方和达到目标误差平方和。参数值向上移动时,根据刻画参数的变化,所有其他参数会调整到最小二乘估计值。从概念上看,这是一组复合的嵌套迭代。但内部可以使用 Johnton 和 DeLong 开发的一组迭代来执行此操作。请参见《SAS/ETS 用户指南》(SAS Institute Inc. 2018)。
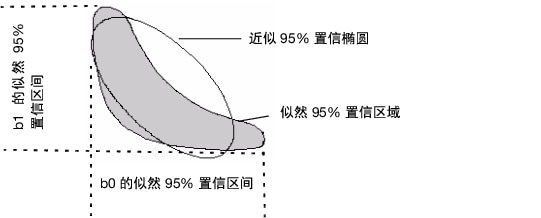
Figure 14.20显示了目标误差平方和或负似然的等高线,最小二乘(或最小损失)解位于阴影区域内。
• 渐近标准误差生成的置信区间使用椭圆近似该区域并在极值处(在水平和垂直的切线处)取参数值。
• 边侧置信限在真实区域(而非近似的椭圆)的极值处查找参数值。
图 14.20 参数的置信限关系图
似然置信区间比根据近似标准误差计算得到的置信区间更可信。若找不到特定的限值,将对下一个限值开始计算。实现收敛很困难时,请尝试以下方法:
• 使用更大的 alpha,这会使置信区间更短,更有可能表现更好
• 放松置信限准则。
需要更多信息?有问题?从 JMP 用户社区得到解答 (community.jmp.com).