 解路径
解路径这两个图的水平尺度以统一尺度的参数估计值量值形式给出。这是 l1 范数,定义为统一尺度的参数估计值的绝对值之和,这些估计值是针对均值的模型估计值。(会从 l1 范数的计算中排除对应于截距、离散参数和零泛滥参数的估计值。)请注意以下事项:
|
•
|
|
•
|
|
•
|
 当前模型指示符
当前模型指示符两个图中的红色垂直实线都对应同一个 l1 范数值,该值是“原始预测变量的参数估计值”报表中显示的解的值。您可以在任意一个图中拖动红色垂直线顶部的箭头来更改罚值的大小,以指示新的当前模型。在验证图中,您还可以点击图中的任意位置来更改模型。拖动红色的垂直线指示新模型时,报表中的结果将相应更新以反映当前选择的模型。垂直虚线仍在最佳拟合模型处。您可以点击“验证图”旁边的重置解按钮,返回初始解的垂直红线和相应结果。对于某些验证方法,验证图提供用于标识可比模型的区域。请参见可比模型区域。
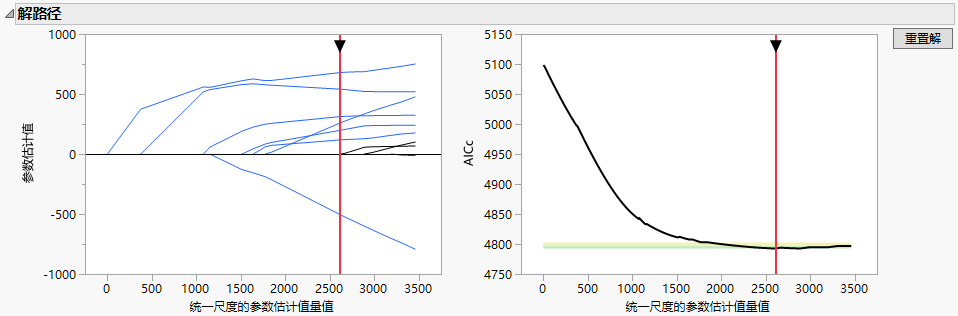
 解路径图
解路径图 解 ID
解 ID“解路径”中的每个解都会在内部分配有一个解 ID。若您调节参数以选择最初显示的解之外的解,相应的解 ID 将显示在“保存脚本”选项所创建的脚本中。解 ID 是设置解 ID( N ) 命令中的值 N。保存解 ID 可确保能够在运行脚本时重新创建选定的解。
 验证图
验证图验证图显示统计量图,这些图描绘模型拟合在调节参数各值间的优劣程度,换言之,即在“统一尺度的参数估计值量值”各值间的优劣程度。标绘的统计图取决于选定的验证方法。对于每种验证方法,验证方法以及相应的验证统计量和区域都列出了所标绘的统计量。所有验证方法都是值越小拟合效果越好。对于 K 重和留一法验证方法以及包含三个以上值的验证列,标绘的统计量是各重之间统一尺度的负对数似然值的均值。
验证方法以及相应的验证统计量和区域中的统一尺度 -对数似然是负对数似然除以为其计算负对数似然的集内的观测数所生成的结果。
|
K 重统一尺度 -对数似然值的均值
|
||
|
K > 3 的值的验证列
|
K 重统一尺度 -对数似然值的均值
|
 可比模型区域
可比模型区域尽管估计某个模型是最佳模型,但也可能存在与该选择相关的不确定性。竞争模型可能拟合得几乎一样好,并且可能包含有用信息。对于 AICc、BIC、K 重和留一法验证方法以及包含三个以上值的验证列,验证图提供标识可能值得考虑的竞争模型的区域。不推荐使用落在这些区域之外的模型。请参见 Burnham and Anderson (2004) 和 Burnham et al. (2011)。
图 6.6显示了 Diabetes.jmp 的验证图,其垂直轴展开以显示这两个区域。
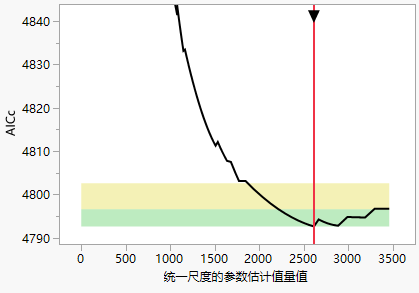
对于这些验证方法,图中显示两个区域。用 V最佳来表示最佳解的验证 BIC、AICc 和 ERIC 值。
|
•
|
|
•
|
|
•
|
|
•
|