 广义回归的示例
广义回归的示例Diabetes.jmp 样本数据表中的数据包括 442 名糖尿病患者的测量值。关注的响应是 Y,即在进行基线测量一年后测量的疾病进展数据。对十个被认定为与疾病进展有关的变量也测量了基线值。本例说明如何使用广义回归方法来生成预测模型。
|
1.
|
|
2.
|
选择分析 > 拟合模型。
|
|
3.
|
|
4.
|
这会将最高达到 2 次(次数框中的默认值)的所有项都添加到模型中。
|
5.
|
|
6.
|
从“特质”列表中选择广义回归。
|
|
7.
|
点击运行。
|
|
8.
|
点击执行。
|
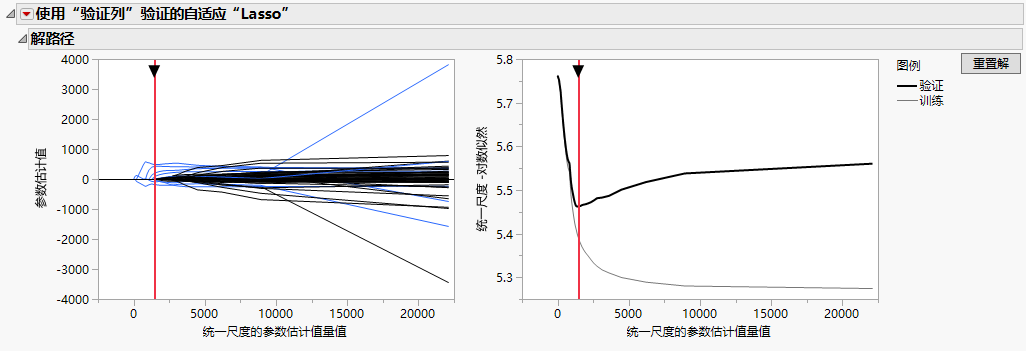
随即显示“使用‘验证列’验证的自适应‘Lasso’”报表。“解路径”报表(图 6.2)显示参数估计值图和统一尺度的负对数似然图。当统一尺度的参数估计值量值减小时收缩量增加。图最右侧的估计值是最大似然估计值。红色的垂直线指示验证准则选择的那些参数值,在该示例中的保留样本由验证列定义。
图 6.2 解路径图
|
9.
|
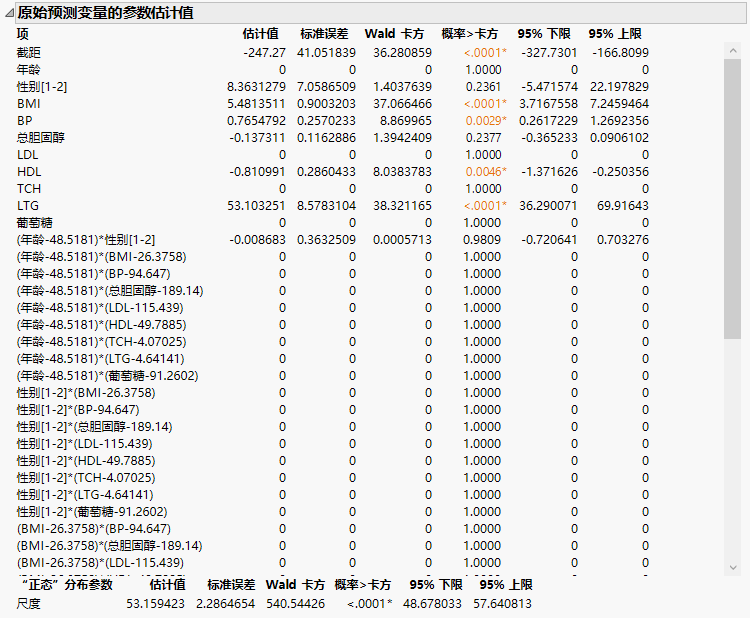
该选项突出显示“原始预测变量的参数估计值”报表(图 6.3)中的非零项和它们在“解路径”图中的路径。同时选定数据表中的对应列。请注意,在 55 个参数估计值中,只有 7 个是非零的。还请注意,估计了正态分布的尺度参数 (sigma),它显示在“原始数据的参数估计值”报表底部的单独表中。
图 6.3 “原始预测变量的参数估计值”报表的一部分
要保存预测公式,请从“使用‘验证列’验证的自适应‘Lasso’”报表的红色小三角菜单中选择保存列 > 保存预测公式。