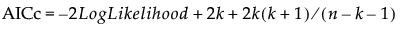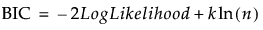JMP 中的很多统计模型使用称为最大似然的方法进行拟合。该方法通过最大化似然函数设法估计模型的参数(它通常用 β 表示)。似然函数(用 L(β) 表示)是在观测的数据值处求得的概率密度函数(或用于离散分布的概率质量函数)之积。给定观测的数据,最大似然估计设法找到使 L(β) 最大化的参数 β 的值。
不必使似然函数 L(β) 最大化,使用似然函数的自然对数的负数 -Log L(β) 更方便。使 L(β) 最大化的问题转换为最小化问题,此时您设法使负对数似然(-对数似然 = -Log L(β))最小化。因此,较小的负对数似然值或负对数似然值的两倍(-2对数似然)指示更好的模型拟合。
通过使用 JMP 中不同的平台,您可以使用负对数似然的值选择模型并执行比较模型拟合效果的定制假设检验。这通过使用似然比检验来完成。在很多 JMP 平台中报告 -2 对数似然的一个原因是完全模型和简化模型 -2 对数似然值的差值是逐近的卡方分布。与这个似然比检验关联的自由度等于两个模型中参数数目的差值 (Wilks 1938)。