该示例使用有关在 2011 年发行的电影的数据。您对全球总收入值特别感兴趣,该值表示总收入。您的潜在预测变量为烂番茄分数、观众打分和类型。两个得分变量为连续的,但是类型是名义型的。在尝试使用“逐步”简化模型前,您想探索相关变量。
|
1.
|
|
2.
|
选择分析 > 分布。
|
|
3.
|
|
4.
|
点击确定。
|
图 5.14 “类型”的分布
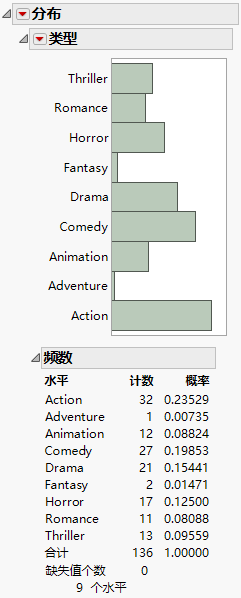
请注意,类型有 9 个水平,因此将用 8 个模型项来表示。进一步的数据探索将揭示:由于缺失数据,“逐步”只考虑 8 个水平。
|
5.
|
|
6.
|
选择分析 > 筛选 > 探索缺失值。
|
|
7.
|
图 5.15 “缺失列”报表
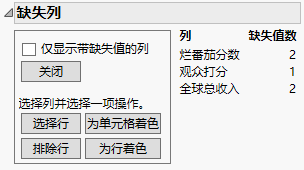
|
8.
|
在“缺失列”报表中,选择列下面列出的三列。
|
|
9.
|
点击选择行。
|
在数据表的“行”面板中,您可以看到选择了三行。因为这三行包含有关预测变量或响应的缺失数据,它们将自动从“逐步”分析中排除。请注意,第 134 行是“Adventure”类别中的唯一一个条目,这意味着将从分析中彻底删除该类别。为了进行“逐步”分析,因此类型只有 8 个类别。既然您已了解缺失数据的影响,接下来将执行“逐步”分析。
|
10.
|
选择分析 > 拟合模型。
|
|
11.
|
|
12.
|
变换后的变量对数[全球总收入]显示在“选择列”列表的底部。
|
13.
|
|
14.
|
从“特质”列表中选择逐步。
|
|
15.
|
点击运行。
|
图 5.16 显示了模型项列表的“当前估计值”表
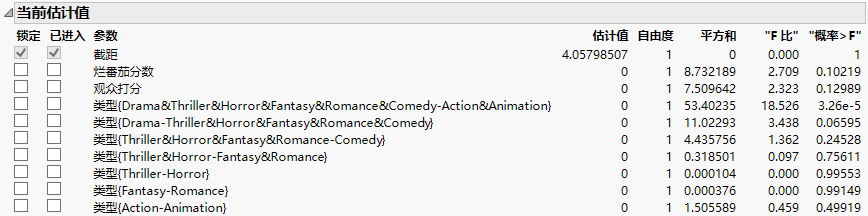
在“当前估计值”表中,请注意类型用 7 个项表示。您将使用其中的两个项构造模型以了解这些项是如何定义的。
|
16.
|
|
17.
|
点击构建模型。
|
显示的第一个项是类型{Drama&Thriller&Horror&Fantasy&Romance&Comedy-Action&Animation}。该变量的格式为类型{A1 - A2},其中 A1 和 A2 用减号分隔。该符号指示根据组间平方和确定的最大化分隔发生在以下两组水平之间:
若您在模型中包含项 Genre{Drama&Thriller&Horror&Fantasy&Romance&Comedy-Action&Animation},则在模型中使用表示该项的临时变换列。该列包含以下值:
显示的第二个项是类型{Drama-Thriller&Horror&Fantasy&Romance&Comedy}。这组水平完全包含在第一个项 (A1) 的第一次拆分中。该符号对比水平:
|
•
|
图 5.17 显示了分层编码中使用的拆分的树
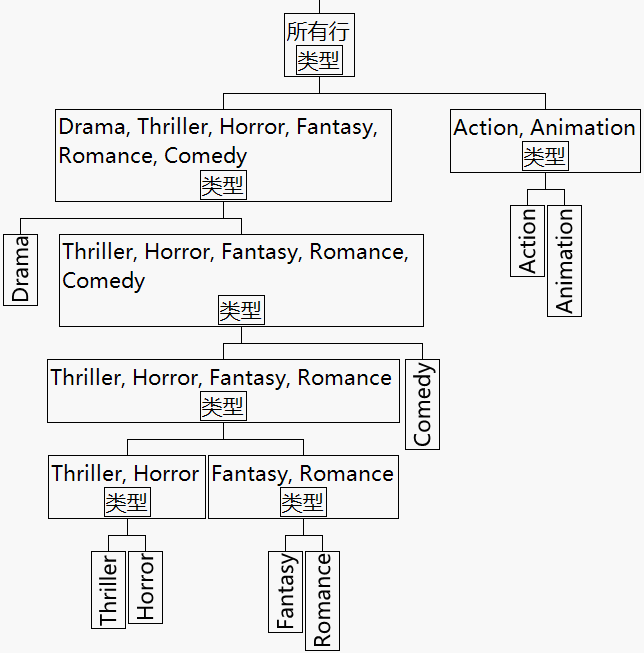
当您使用合并规则或限制规则时,项无法进入模型,除非层次中该项上层的所有项都进入了模型。例如,若您使类型{Action-Animation}进入,则 JMP 也将使类型{Drama&Thriller&Horror&
Fantasy&Romance&Comedy-Action&Animation}进入。
Fantasy&Romance&Comedy-Action&Animation}进入。