Diabetes.jmp 样本数据表包含十个基线变量,用于对疾病发展进行建模。在本例中,您对连续型基线变量聚类。
|
1.
|
|
2.
|
选择分析 > 聚类 > 聚类变量。
|
|
3.
|
不能包括性别列,因为“聚类变量”要求提供数值型连续变量。
|
4.
|
点击确定。
|
图 15.2 糖尿病数据的聚类变量报表
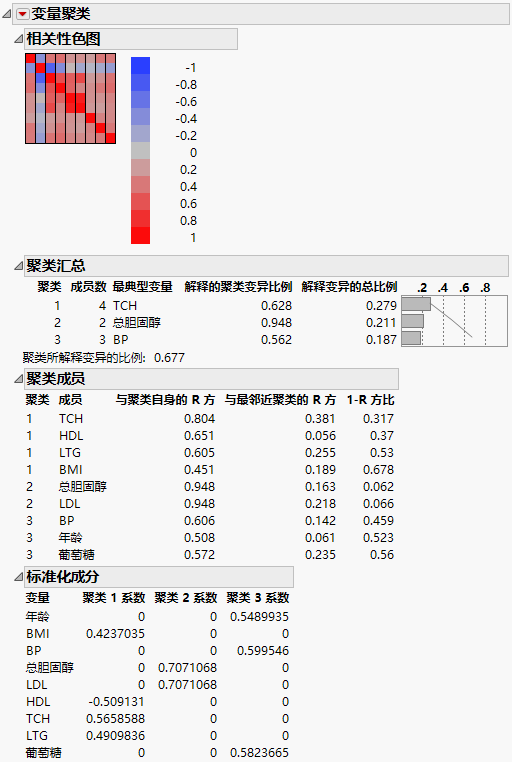
|
•
|
|
•
|
|
•
|