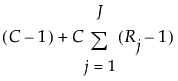J 个变量的多维列联表包含 W = R1*...*RJ 个单元格。其中的每一个单元格依据其针对 J 个变量的响应模式来定义。因此,每个响应模式是形式为 y = y1, ..., yj 的 J-长度向量。将 Y 定义为所有响应模式视为行向量的 J x W 数组。Y 中的每个元素 yw, 都具有概率 Pr(yw)。这些概率之和为 1:
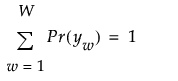
|
•
|
C 是潜在类模型中的聚类数。
|
|
•
|
|
•
|
|
•
|
|
•
|

该方程是您从“潜在类分析”红色小三角菜单中选择“保存混合和聚类公式”选项时保存至数据表的 Prob Formula Cluster 公式的分母。Prob Formula Cluster 列中的公式给出 Pr(聚类 = c | yw),其等于 Pr(yw, 聚类 = c) / Pr(yw)。