偏最小二乘基于解释变量 (X) 的线性组合(称为因子)来拟合线性模型。这些因子是通过将 X 与一个或多个响应 (Y) 之间的协方差最大化得到的。这样,PLS 可利用 X 和 Y 之间的相关性来揭示底层的潜在结构。这些因子实现了解释响应变异和预测变量变异的组合目标。当您的 X 变量数比观测数多或 X 变量高度相关时,偏最小二乘特别有用。
NIPALS 方法一次提取一个因子。用 X = X0 表示预测变量的中心化和统一尺度的矩阵,用 Y = Y0 表示响应值的中心化和统一尺度的矩阵。PLS 方法从预测变量的一个线性组合 t = X0w 开始,其中 t 称为得分向量,w 是相关的权重向量。PLS 方法通过 t 的回归来预测 X0 和 Y0:
 =
= 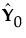 =
= 特定线性组合 t = X0w 是在指定某些响应线性组合 u = Y0q 的情况下具有最大协方差 t´u 的组合。另一特性是 X- 和 Y-权重 w 和 q 与协方差矩阵 X0´Y0 的第一个左奇异向量和右奇异向量成比例。或者分别等效于 X0´Y0Y0´X0 和 Y0´X0X0´Y0 的第一个特征向量。
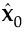

SIMPLS 算法开发的目的在于优化统计准则:它寻找在 X 得分是正交的前提下使 X 和 Y 的线性组合之间的协方差最大化的得分向量。不同于 NIPALS,该算法缩小了矩阵 X0 和 Y0 ,SIMPLS 缩小的是叉积矩阵 X0´Y0。