 具有分类预测变量的高斯过程模型的示例
具有分类预测变量的高斯过程模型的示例本例使用 Algorithm Data.jmp 样本数据表。这些数据为对 CPU 时间的模拟,来自一个 50 次的空间填充设计实验。Algorithm Factors.jmp 样本数据表提供设计的因子和设置。该设计有三个连续因子和两个分类因子。目标是要使用同时包含连续和分类因子的高斯过程模型预测 CPU 时间。
|
1.
|
|
2.
|
选择分析 > 专业建模 > 高斯过程。
|
|
3.
|
|
4.
|
 要运行分析,请保持“快速 GASP”处于选中状态。点击
要运行分析,请保持“快速 GASP”处于选中状态。点击
图 15.7 “Algorithm Data”报表
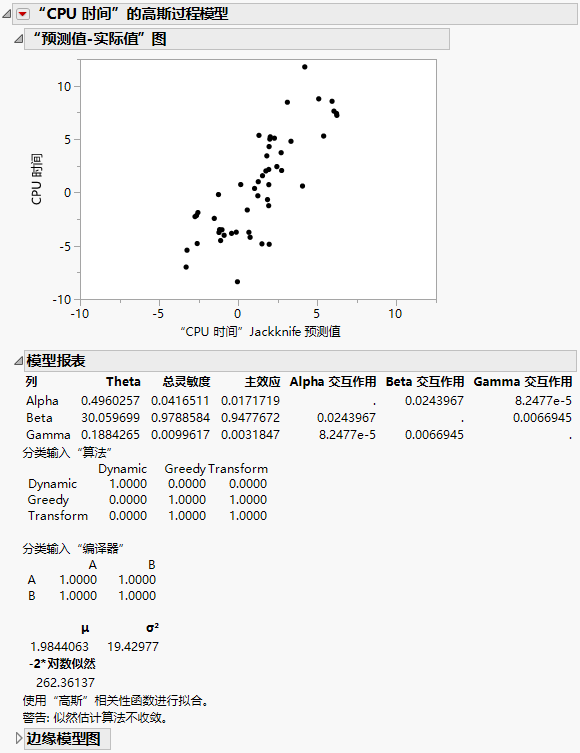
“预测值-实际值”图显示实际 CPU 时间与预测 CPU 时间之间存在强相关性。这表明高斯过程预测模型是真实函数的良好近似。在“模型报表”中,Beta 预测变量具有最高的总灵敏度。这表明在连续预测变量中,Beta 解释了响应中的大多数变异。每个分类预测变量(算法和编译器)都有一个单独的“分类输入”矩阵。这些矩阵是相关性矩阵,并且显示每个分类预测变量的水平之间的相关性。这些矩阵的非对角线元素是 τ 参数。