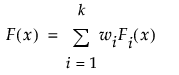
其中,Fi(x) 是受支持的分布之一,k 是混合模型中的成分个数,wi 是总和为 1 的正权重。“拟合混合模型”选项尝试标识从每个成分分布 Fi(x) 中抽取的观测聚类。它估计混合模型的参数以及从任意给定成分中抽取观测的概率。
拟合方法基于有关相应聚类的假设,该方法称为“起始值方法”。假定您指定了 k 个分布。有三种“起始值方法”:
|
•
|
“可分隔的聚类”假定成分分布对某些观测的影响比对其他观测更深。对于可分隔的聚类,k 个密度中的每一个都具有可标识的模式并定义一个聚类。
|
|
•
|
|
1.
|
选择混合分布中具有给定分布的成分个数。“数量”值的总和为 k,即混合分布中密度的个数。
点击执行可拟合所需的混合模型。“模型列表”会随您拟合的模型更新,同时添加具有混合模型名称的报表。
“模型列表”报表会列出您拟合的混合分布。该报表提供每个混合分布的参数数目、实际观测数,以及 AICc、-2*对数似然和 BIC 统计量。有关这些统计量的更多详细信息,请参见《拟合线性模型》手册中的“似然、AICc 和 BIC”。
|
•
|
比较准则红色小三角选项不影响“模型列表”中模型的顺序。
|
为混合模型中的每个分布提供了参数估计值。“参数”列还包括名为“对应部分 <i>”的参数,其中 i = 1, 2, .., k-1。这些是混合模型的权重 wi 的估计值。由于这些权重的总和为 1,所以可以根据前 k - 1 个权重计算出第 k 个权重。
|
1.
|
|
2.
|
选择分析 > 可靠性和生存 > 寿命分布。
|
|
3.
|
|
4.
|
点击确定。
|
|
5.
|
从“寿命分布”旁边的红色小三角菜单中选择拟合混合模型。
|
|
6.
|
|
7.
|
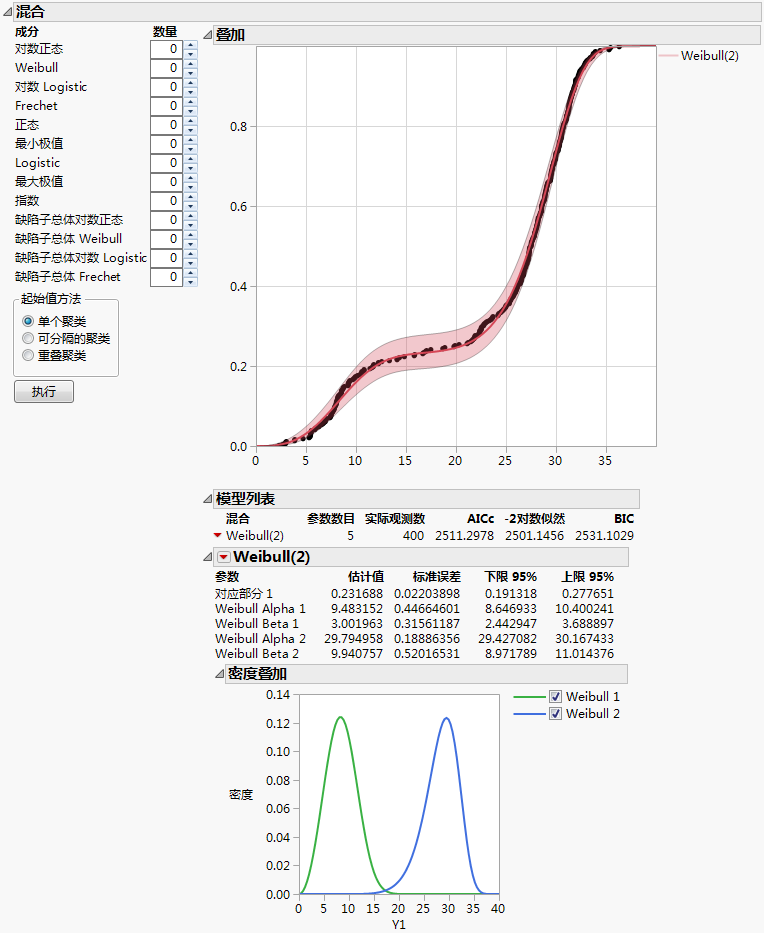
在“起始值方法”面板中选择可分隔的聚类。
|
|
8.
|
点击执行。
|
图 3.10 拟合“Weibull(2)”的混合模型
|
9.
|
|
10.
|
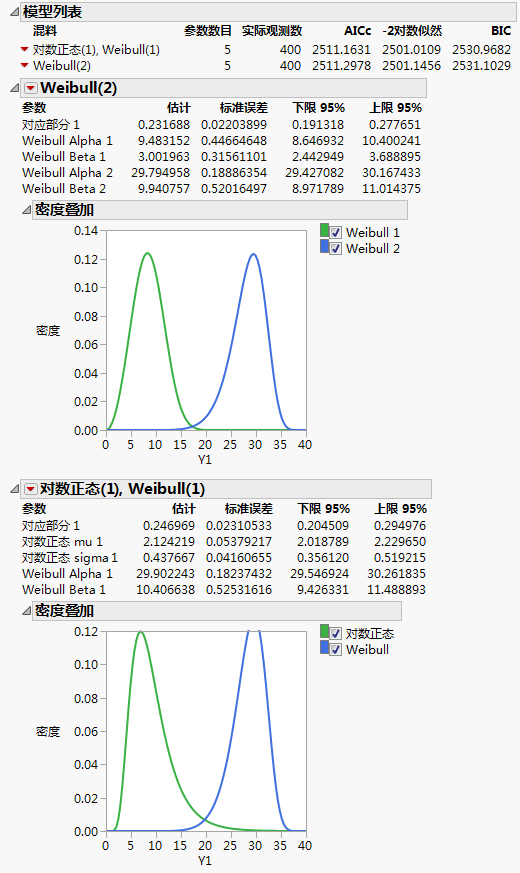
点击执行。
|
图 3.11 拟合“对数正态(1),Weibull(1)”的混合模型
|
1.
|
|
2.
|
选择分析 > 分布。
|
|
3.
|
|
4.
|
选中仅显示直方图。
|
|
5.
|
点击确定。
|
|
6.
|
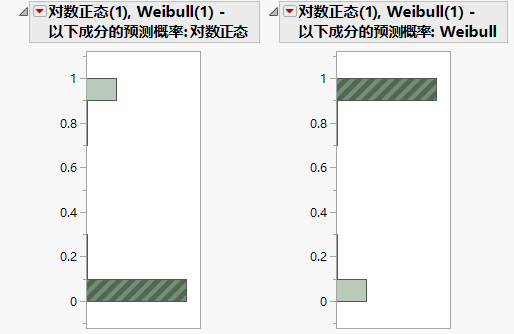
在对数正态(1),Weibull(1) - 以下成分的预测概率: Weibull 的直方图中,点击与接近 1 的值对应的直条。
|
图 3.12 混合概率的直方图