Process Description
Recode Missing Genotypes
JMP Genomics processes require that missing genotypes be represented using specific formats. Recode Missing Genotypes creates a modified data set in which nonstandard formats used to represent missing genotypes or alleles are replaced with the specific values required by the Genetics processes: blank ( ) for character genotypes or alleles and a period (.) for numeric genotypes or alleles.
What do I need?
One Input Data Set, containing the marker data is required to run the Recode Missing Genotypes process. The samplegmdata_missgeno_a.sas7bdat data set used in the following example represents a modification of the computer-generated samplegmdata.sas7bdat data set described in Data Sets Used in JMP Genomics Processes. This data set consists of 1000 rows of individuals with 60 columns corresponding to data on these individuals. Marker data is presented in the one-column format. This data set is partially shown below. Note that this is a wide data set; markers are listed in columns, whereas individuals are listed in rows. Missing genotypes, such as the one that is circled, are represented with an asterisk (*).
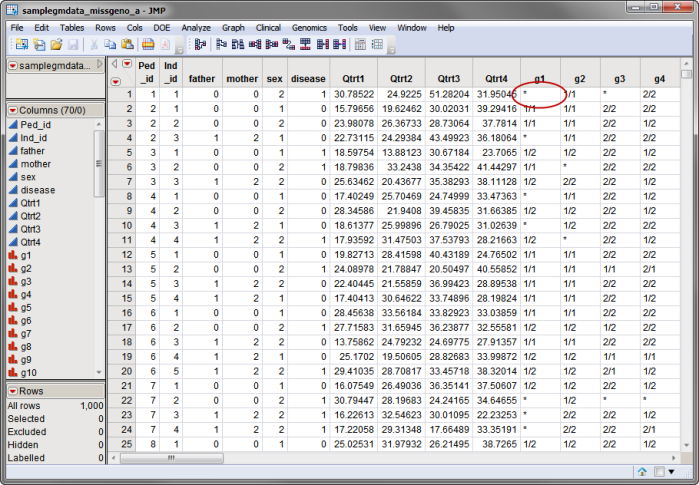
This data set is included in the Sample Data folder.
For detailed information about the files and data sets used or created by JMP Genomics software, see Files and Data Sets.
Output/Results
Output from this process is accessed from a Results window. Refer to the Recode Missing Genotypes output documentation for detailed descriptions and guides to interpreting your results.