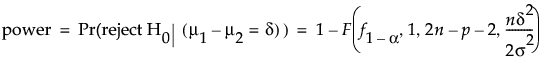JMP 14.2オンラインマニュアル
はじめてのJMP
JMPの使用法
基本的な統計分析
グラフ機能
プロファイル機能
実験計画(DOE)
基本的な回帰モデル
予測モデルおよび発展的なモデル
多変量分析
品質と工程
信頼性/生存時間分析
消費者調査
スクリプトガイド
スクリプト構文リファレンス
JMP iPad Help (英語)
JMP Interactive HTML (英語)
機能インデックス
JMP統計機能ガイド
このバージョンのヘルプはこれ以降更新されません。最新のヘルプは
https://www.jmp.com/support/help/ja/15.2
からご覧いただけます。
実験計画(DOE)
•
検出力と標本サイズ
•
[2標本平均]
• [2標本平均]の統計的詳細
前へ
•
次へ
[2標本平均]の統計的詳細
[2標本平均]の計算は、以下のような仮説検定に対する、従来の両側
t
検定に対するものです。
検出力は次のように計算されます。
この式で、
α
は有意水準。
n
はグループごとの標本サイズ。
p
は追加パラメータの個数。
δ
は検出する差。
f
1-a
は、
F
(1, 2
n
-
p
- 2)分布の累積確率(1 -
α
)に対する分位点。
F
(
x
, df
1
, df
2
,
nc
)は、自由度
df
1
および
df
2
と非心度パラメータ
nc
を持つ
F
分布の
x
における累積確率。
検出力を求めるときにはF分布の累積分布関数が使われていますが、
δ
および
n
を求めるときには数値的なアルゴリズムが使われています。
JMPにおける計算についての詳細は、Barker(
2011
, Section 2.2)を参照してください。