「カスタム計画」プラットフォームによって作成されたデータテーブルには、「モデル」スクリプトが保存されます。このスクリプトを使うと、データ分析を簡単に行えます。カスタム計画のテーブルを参照してください。実験を行い、データを入力した後、このスクリプトを実行します。すると、「モデルのあてはめ」ウィンドウが開き、「カスタム計画」ウィンドウの「モデル」アウトラインで指定した効果が表示されます。
|
1.
|


|
3.
|
[ダイアログを開いたままにする]チェックボックスをオンにします。
|
|
4.
|
[実行]をクリックします。
|

|
•
|
「予測値と実測値のプロット」は、モデルが有意であることを示しています。プロットの下にあるP = 0.0041は、モデル全体に関する検定の有意確率です。
|
|
•
|
|
•
|
「温度」と「挽き」は統計的に有意でないので、ここでは、これらの因子は応答に影響していないと判断し、ランダムな誤差とみなして分析してみましょう。有意な効果のモデルパラメータについて、より精度の高い推定値を得るために、有意でない効果を除外して、再びモデルをあてはめてみましょう。
|
1.
|
|
2.
|
[削除]をクリックします。
|
|
3.
|
|
4.
|
[実行]をクリックします。
|

|
•
|
「尺度化した推定値」レポートは、場所[1]と場所[3]における「濃度」の平均が、全体的な平均とかなり異なることを示しています。
|
|
•
|

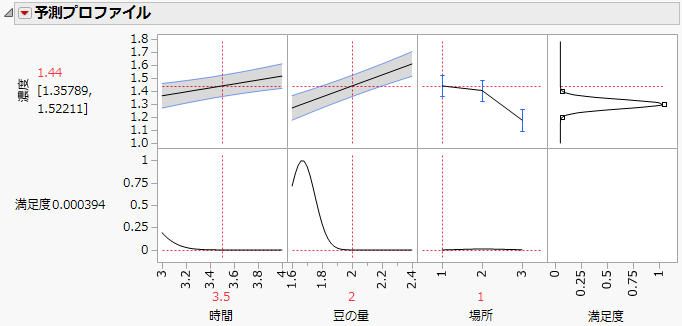
この計画を作成するとき、応答の目標を[目標値に合わせる]、範囲を1.2~1.4に設定しました。JMPは、それらの設定に応じた満足度関数を自動的に作成します。詳細については、「因子」(80ページ)を参照してください。
予測プロファイルにおいて、次のことを確認してください。
|
•
|
上段における最初の2つのプロットは、残りの因子は固定しながら、該当する1つの因子を変化させたときに、「濃度」がどのように変化するかを表しています。たとえば、「時間」におけるプロットは、「豆の量」が2であるときに、「濃度」の予測値が「時間」に対してどのように変化するかを示しています。
|
|
•
|
上段のプロットの左側に表示されている数値は、指定されている因子設定に対する、「濃度」の予測値(赤字)と、その期待値に対する信頼区間です。
|
|
•
|
上段の右端のプロットは、「濃度」の満足度関数です。この例の満足度関数は、目標値である1.3において、満足度が最も高くなっています。満足度は、その目標値から離れるほど低くなり、 限界値の1.2と1.4でほぼ0になります。
|
「時間」と「豆の量」の列で赤い縦の点線をドラッグし、さまざまな因子設定を試してみましょう。モデル内に交互作用はないので、このプロファイルから「豆の量」が増えるほど「濃度」が増すことがわかります。また、「時間」よりも「豆の量」から「濃度」は大きな影響を受けるようです。
「場所」はブロック因子なので、「予測プロファイル」には表示されません。ただし、「濃度」の予測値が「場所」によってどのように変化するかを確認したい場合もあるでしょう。「予測プロファイル」に「場所」を含めるには、次の手順に従います。
|
1.
|
「予測プロファイル」の赤い三角ボタンのメニューから、[因子グリッドのリセット]を選択します。
|
|
2.
|
「場所」の下の[表示]ボックスを選択します。
|
|
3.
|
「場所」の下の[因子設定のロック]ボックスを選択解除します。
|

|
4.
|
[OK]をクリックします。
|
「予測プロファイル」に「場所」が表示されます。
|
5.
|
「場所」のどちらかのプロットをクリックします。すると、赤い縦の点線が描かれます。
|
|
6.
|
赤い縦の点線を場所1に移動します。
|
|
7.
|
赤い縦の点線を場所3に移動します。
|

場所1では、計画領域の中心における「濃度」の予測値は1.44となっています。一方、場所3では、「濃度」の予測値は1.18となっています。これらの予測値には差があるので、「場所」によるばらつきを考慮する必要があることを示唆しています。「場所」によるばらつきを小さくできれば、「濃度」を安定させることができます。つまり、「場所」によるばらつきを小さくできれば、3カ所のどの場所でも最適になるような、「時間」と「豆の量」を設定することができます。