“排序后的估计值”选项可生成在筛选情形下使用的“参数估计值”报表版本。若设计不饱和,“排序后的估计值”报表提供“参数估计值”报表所显示的信息,但其中除截距之外的所有项都按照显著性的降序排列(图 3.21中的第二个报表)。若设计是饱和的,则提供伪 t 检验。这些检验基于 Lenth 伪标准误差 (Lenth 1989)。请参见Lenth PSE。
|
1.
|
|
2.
|
选择分析 > 拟合模型。
|
|
3.
|
|
4.
|
确保 2 显示在靠近窗口底部附近的次数框中。
|
|
5.
|
|
6.
|
点击运行。
|
|
7.
|
从红色小三角菜单中选择估计值 > 排序后的估计值。
|
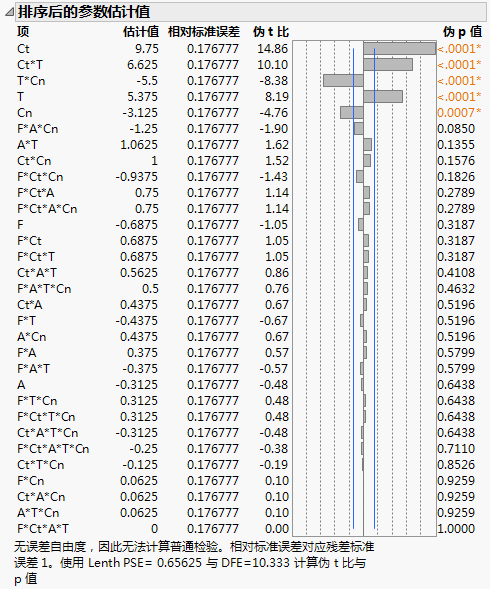
图 3.21 排序后的参数估计值
|
•
|
效应按照 t 比的绝对值排序,最显著的效应显示在顶部。
|
|
•
|
条形图显示 t 比,其中使用垂直线来显示 0.05 显著性水平的临界值。
|
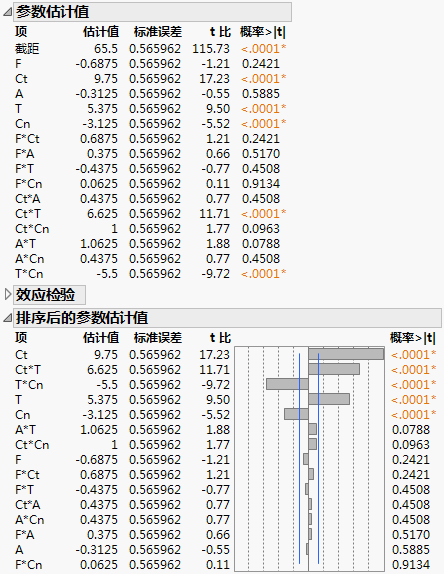
筛选实验经常涉及完全饱和的模型,这种模型中没有足够的自由度来估计误差。在这些情况下,“排序后的估计值”报表(图 3.21)提供相对标准误差并使用 Lenth 伪标准误差 (PSE) 构造 t 比和 p 值。这些量的名称中标有伪。请参见Lenth PSE和伪 t 比。通过一条注释来解释更改并显示 PSE。
参数估计值以排序后的顺序显示,最小的 p 值列在最前面。
估计值的 t 比,使用伪标准误差计算得到。Lenth PSE 的值显示在报表底部的注释中。
Lenth 伪标准误差 (PSE) 是 Lenth (1989) 提出的剩余误差的估计值。它基于效应稀疏原则:在筛选实验中,相对较少的效应是活跃的。不活跃效应表示随机噪声并构成 Lenth 估计值的基础。
若相对标准误差相等,Lenth PSE 会显示在报表底部的注释中。伪 t 比计算如下:
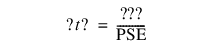
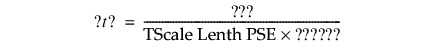
|
1.
|
|
2.
|
选择分析 > 拟合模型。
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
点击运行。
|
|
7.
|
从“响应‘Y’”旁边的红色小三角菜单中,选择估计值 > 排序后的估计值。
|
图 3.22 饱和模型的“排序后的参数估计值”报表