处理参数估计值时,您必须了解 JMP 如何对名义型和有序型列编码。有关如何对名义型列编码的详细信息,请参见“定制检验”示例的详细信息。有关如何对有序型列编码和建模的完整详细信息,请参见名义型因子和有序型因子。
|
1.
|
|
2.
|
选择分析 > 拟合模型。
|
|
3.
|
|
4.
|
|
5.
|
点击运行。
|
|
6.
|
从“响应‘Y’”旁边的红色小三角菜单中,选择估计值 > 扩展后的估计值。
|
“扩展后的估计值”报表随同“参数估计值”报表显示在图 3.23中。请注意,项“药物[f]”的估计值显示在“扩展后的估计值”报表中。该检验的原假设为:药物 f 组的均值与总均值无差异。“药物[f]”的检验在 0.05 水平下显著,这表明药物 f 组的响应均值与总响应存在差异。有关更多详细信息,请参见“扩展后的估计值”检验的解释。
图 3.23 “参数估计值”与“扩展后的估计值”的比较
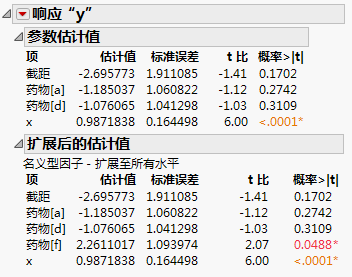
假定模型由一个包含 n 个水平的名义型因子构成。该因子由 n-1 个指标变量表示,n-1 个水平中的每个水平都对应一个指标变量。与 n-1 个指标变量中的任意一个变量对应的参数估计值都是该水平的响应均值与所有水平的响应平均值之间的差值。这种表示形式是由于 JMP 对名义型变量编码的方式造成的(请参见“定制检验”示例的详细信息)。参数估计值通常解释为该水平的效应。
例如,在 Cholesterol.jmp 样本数据表中,考虑单个因子治疗和响应 6 月下午。与治疗[A] 这个项(或指标变量)关联的参数估计值是治疗 A 的 6 月下午的均值与 6 月下午的总均值之间的差值。
名义型变量所有水平的效应被限制为总和为零。考虑水平排序中的最后一个水平(也就是使用 –1s 编码的水平)的效应。该水平的效应是其他 n-1 个水平的效应之和的负数。由此判定:最后一个水平的效应是其他 n-1 个水平的参数估计值之和的负数。
|
•
|
|
•
|
|
•
|
若高阶交互作用中涉及名义型因子,“扩展后的估计值”报表会很长。例如,二水平名义型因子的五因子交互作用仅生成一个参数估计值,但包含 25 = 32 个扩展效应,所有效应都相同,直到符号改变。
|