基于 X 变量的水平为“典型图”和“典型三维图”中的点着色。将颜色标记添加到数据表中的行。该选项等效于选择行 > 按列设定颜色或标记并选择 X 变量。它也等效于右击图形并选择行图例,然后按分类列着色。
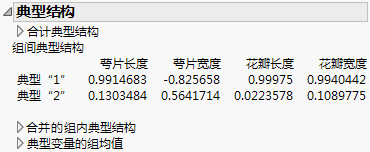
显示或隐藏“典型结构”报表。请参见显示典型结构。对于“宽线性”判别方法不可用。
提示:在脚本中,将脚本命令 Save to New Data Table 发送到“判别”对象会将以下内容保存到新数据表:典型变量的组均值、标准化得分系数的射线尺度为 1.5 的双标图射线以及典型得分。对于“宽线性”判别方法不可用。
“典型详细信息”报表显示说明协变量和分组变量 X 之间的关系的检验。相关矩阵显示在报表底部。

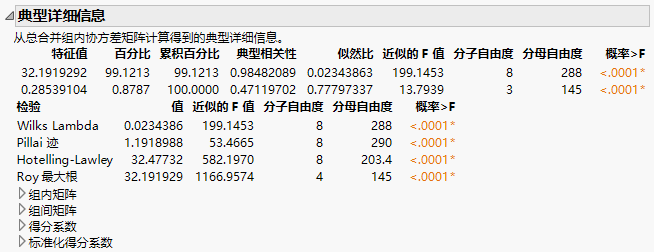
协变量和分类变量 X 所定义的组之间的典型相关性。假定您定义数值指标变量来表示 X 所定义的组。然后使用协变量作为一组变量并使用表示 X 中的各组的指标变量作为另一组变量来执行典型相关性分析。“典型相关性”值是从该分析得到的典型相关性值。
列出针对在各组上协变量的均值相等这个原假设的四个标准检验:Wilk Lambda、Pillai 迹、Hotelling-Lawley 和 Roy 最大根。请参见多元检验和判别分析附录中第 近似 F 检验。
相应检验的 p 值。
用于根据原始数据计算典型得分的系数。这些是用于选项典型选项 > 保存典型得分的系数。有关如何计算这些系数的详细信息,请参见《SAS/STAT 14.3 用户指南》中的“CANDISC 过程”一章 (SAS Institute Inc. 2017a)。
用于根据标准化数据计算典型得分的系数。经常称为典型权重。有关如何计算这些系数的详细信息,请参见《SAS/STAT 14.3 用户指南》中的“CANDISC 过程”一章 (SAS Institute Inc. 2017a)。