“‘<k>’个聚类的潜在类模型”报表
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
|
•
|
默认情况下,指定聚类数的模型汇总显示在每个“潜在类模型”报表的顶部。模型汇总包含 -对数似然、参数个数、BIC 和 AIC。这些汇总值可用于确定模型对数据拟合的好坏程度。“-对数似然”、“BIC”和“AIC”的值越小表示拟合效果越好。详细信息,请参见《拟合线性模型》手册中的“似然、AICc 和 BIC”。“参数数目”值提供潜在类模型中的唯一参数个数。详细信息,请参见“潜在类分析”平台的统计详细信息。
图形化显示将条件概率值显示为份额图。对于每个聚类和每个 Y,用水平堆叠条形图绘制了给定聚类成员关系的条件概率。对于二值或名义型响应列,这些图中每个响应的百分比都加总为 1。对于多重响应列,百分比是每个类别的较低级别的百分比,加总不为 1。直条的堆叠按照值表中变量的顺序展示。您还可以将光标置于直条上,以查看变量的水平或类别。
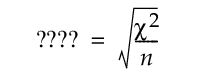
“LR Logworth”列中的每个值显示 -log10(pLR),其中 pLR 是由期望计数构成的列联表的对数似然比检验 p 值。超过 2 的 Logworth 值对应于在 0.01 显著性水平下的显著性。
MDS 图对每个聚类都包含一个点,并且在默认情况下显示出来。它是聚类邻近关系的二维表示。越邻近的聚类越相似。该图基于 ρ 参数的相异度矩阵创建。有关 MDS 图的详细信息,请参见第 153 页的“多维尺度化”一章。