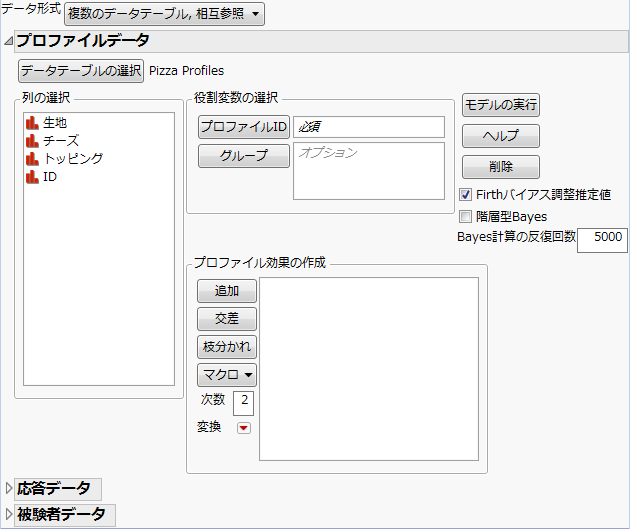
[複数のデータテーブル, 相互参照]データ形式の起動ウィンドウは、複数のデータテーブル用の起動ウィンドウで、「Pizza Profiles.jmp」をプロファイルのデータテーブルとして使用しています。
プロファイルのデータテーブルには、各選択肢の属性を示すデータを保存してください。データテーブルの各列が1つの属性に対応するように、 また、各行が1つのプロファイルに対応するように、データを作成してください。さらに、各プロファイルのID を含んだ列を設けてください。プロファイルデータテーブルと設定後の「プロファイルデータ」アウトラインは、「Pizza Profiles.jmp」データテーブルと、列を指定した後の「プロファイルデータ」パネルです。

属性の組み合わせ(プロファイル)を識別するためのID。[プロファイルID]によってプロファイルのデータテーブルにおける各行を一意に識別できない場合は、[グループ]変数も指定する必要があります。その場合、[グループ]列と[プロファイルID]列の組み合わせによって各行が一意に識別できるように、[グループ]列を追加してください。
「プロファイルID」列とともに使用したときに、各選択肢集合を一意に示すことができる列。たとえば、[プロファイルID]の値が「1」である行が2つあったとします。データテーブルにおいて、一方の選択肢集合に対しては「調査」列が「A」で、他方の選択肢集合に対しては「調査」列が「B」であるなら、その「調査」列を[グループ]列に指定します。
「プロファイル効果の作成」パネルについては、『基本的な回帰モデル』の「モデルの指定」章にある「モデル効果の構成」の節を参照してください。
Firth法は、バイアス修正を伴う最尤推定であり、通常の最尤推定に比べ、推定や検定がより良い性質をもちます。さらに、ロジスティックモデルなどで生じる分離(separation)の問題も改善できます。ロジスティック回帰における分離問題については、Heinze and Schemper(2002)を参照してください。
 階層型Bayes
階層型Bayes Bayes計算の反復回数
Bayes計算の反復回数応答のデータテーブルには、被験者ID・選択肢のプロファイルID・選択されたプロファイルIDの列を設けてください。そして、各被験者と選択肢集合ごとに1行ずつ保存してください。選択肢集合のグループが複数ある場合は、グループ変数を使って選択肢集合を区別してください。応答データテーブルと設定後の「応答データ」アウトラインは、「Pizza Responses.jmp」データテーブルと、列を指定した後の「応答データ」パネルです。

「選択されたプロファイルID」列と共に使用したときに、各選択肢集合を一意に示すことができる列。
度数を含んだ列。度数がnである行は、データにn回登場しているものとして計算に使用されます。度数が1未満である行や、欠測値である行は、分析に使用されません。
被験者のデータテーブルは、必須ではなく、モデルに被験者効果を含めたいときに使用します。このデータテーブルの列には、被験者ID(応答データテーブルでも使用されているもの)、および、被験者の属性を含めてください。被験者に関するデータは応答のデータテーブルに含めてもかまいませんが、その場合も、「被験者データ」アウトラインで被験者効果を指定する必要があります。被験者データテーブルと設定後の「被験者データ」アウトラインは、「Pizza Subjects.jmp」データテーブルと、列を指定した後の「プロファイルデータ」パネルです。

「モデル効果の構成」パネルについては、『基本的な回帰モデル』の「モデルの指定」章にある「モデル効果の構成」の節を参照してください。