JMP 14.2 联机文档
发现 JMP
使用 JMP
基本分析
基本绘图
刻画器指南
实验设计指南
拟合线性模型
预测和专业建模
多元方法
质量和过程方法
可靠性和生存方法
消费者研究
Scripting Guide
JSL Syntax Reference
该帮助的版本不再更新,请参见
https://www.jmp.com/support/help/zh-cn/15.2
获取最新的版本.
预测和专业建模
• 响应筛选
上一个
•
下一个
响应筛选
在大型数据中检验很多响应
大型数据集的分析涉及对某一零件或某一生物体取数百或数千个测量值,因此分析这样的数据集需要创新性的方法。但是若没有合适的方法,要对多个响应变量进行因子效应检验且保证结果不会产生误导会比较困难。
“响应筛选”自动执行对大量的响应进行检验的过程。为了支持数据探索,您的检验结果和汇总统计量显示在数据表而不是报表中。假发现率方法可以防止对检验的显著性做出错误的判定。p 值图的尺度使用 LogWorth 进行了调整,这使得它们易于解释。
因为大型数据集通常很零乱,“响应筛选”提供了解决不规则分布数据和缺失数据的方法。稳健估计方法允许离群值留在数据中,但是降低了检验对这些离群值的敏感度。缺失数据选项允许在分析中包括缺失值。使用这些功能,您无需进行大量的数据质量检查工作就可以直接进行数据分析。
当您有很多观测值时,即使没有实际意义的差值也可能在统计上是显著的。“响应筛选”提供检测实际差值的检验,您在该检验中指定实际要检测的差值。另一方面,您可能想知道差值是否未超过给定的量值,即均值是否等价。为此,“响应筛选”提供了等价性检验。
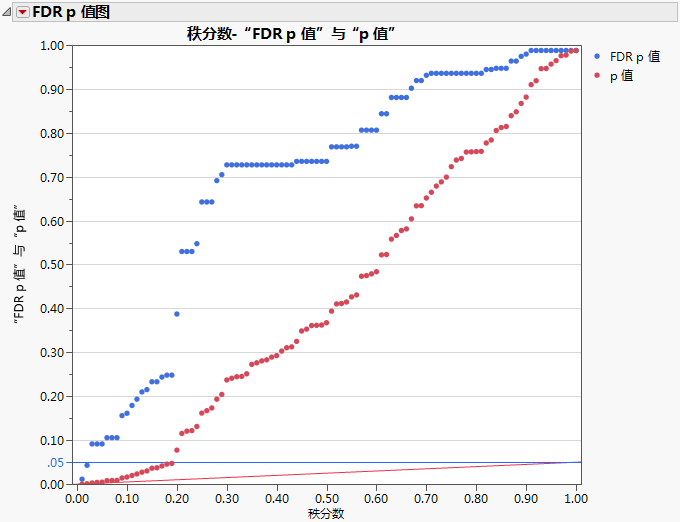
图 18.1
响应筛选图的示例
目录
“响应筛选”平台概述
响应筛选的示例
启动“响应筛选”平台
“响应筛选”报表
FDR p 值图
效应大小-FDR LogWorth
R 方-FDR LogWorth
“PValues”数据表
“PValues”数据表列
为稳健选项添加的列
“PValues”数据表脚本
“响应筛选”平台选项
“Means”数据表
“Compare Means”数据表
“拟合模型”中的“响应筛选”特质
在“拟合模型”中启动“响应筛选”
“拟合响应筛选”报表
“PValues”数据表
“Y Fits”数据表
响应筛选的更多示例
实际显著性检验和等价性检验的示例
“LogWorth 最大值”选项的示例
稳健拟合的示例
“响应筛选”特质
“响应筛选”平台的统计详细信息
假发现率